场景分析
▼
由于公司zabbix的历史数据存储在elasticsearch中,有个需求是尽可能地把监控的历史数 据存储的长一点,最好是一年,目前的情况是三台ES节点,每天监控历史数据量有5G,目前最多可存储一个月的数据,超过30天的会被定时删除,每台内存分了8G,且全部使用机械硬盘,主分片为5,副本分片为1,查询需求一般只获取一周的历史数据,偶尔会有查一 个月到两个月历史数据的需求。
节点规划
▼
为了让ES能存储更长的历史数据,以及考虑到后续监控项添加导致数据的增长,我将节点 数量增加至4节点,并将部分节点内存提高,部分节点采用SSD存储

优化思路
▼
对数据mapping重新建模,对str类型的数据不进行分词,采用冷热节点对数据进行存储, 前七天数据的索引分片设计为2主1副,索引存储在热节点上,超过七天的数据将被存储在 冷节点,超过30天的索引分片设置为2主0副本,ES提供了一个_shrink的api来进行压缩。由于ES是基于Lucene的搜索引擎,Lucene的索引由多个segment组成,每一个段都会消耗 文件句柄,内存和CPU运行周期,段数量过多会使资源消耗变大,搜索也会变慢,这里我将 前一天的索引分片强制合并为1个segment,修改refresh的时间间隔至60s,减少段的产生 频率。对超过3个月的索引进行关闭。以上操作均使用ES的管理工具curator来定时执行。
Zabbix与ES的对接操作
▼
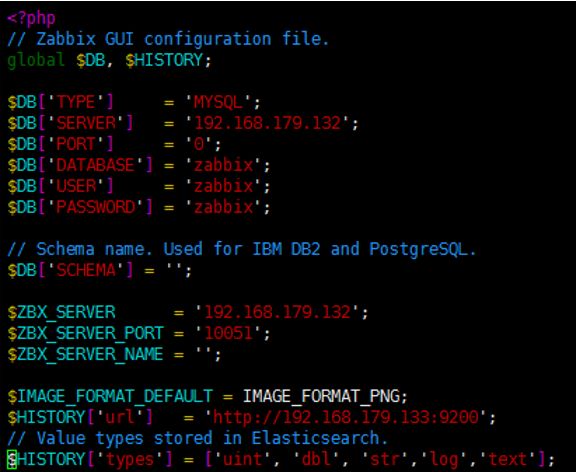
1.修改/etc/zabbix/zabbix_server.
conf,添加如下内容
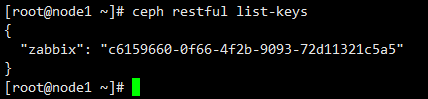
ES地址填写集群中任意一个节点就可以

2.修改/etc/zabbix/web/zabbix.conf.
php 添加如下内容
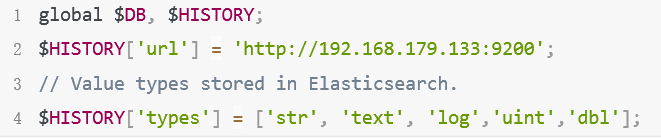
3.修改ES配置文件,添加冷热节点的标签
vim elasticsearch.yml
热节点配置
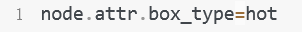
冷节点配置

4.在es上创建模板和管道
每种数据类型的模板都需要创建,可以根据elasticsearch.map文件来获取mapping的信息,模板定义内容有匹配的索引,主副分片数设置,refresh间隔,新建索引分配节点设置以及 mapping的设置,这里我只是以uint和str数据的索引为例。




定义管道的作用是对写入索引之前的数据进行预处理,使其按天产生索引。

5.修改完成后重启zabbix,并查看zabbix是否有数据

使用curator对索引进行操作
▼
curator官方文档地址如下
https://www.elastic.co/guide/en/elasticsearch/client/curator/5.8/installation.html
1.安装curator

2.创建curator配置文件
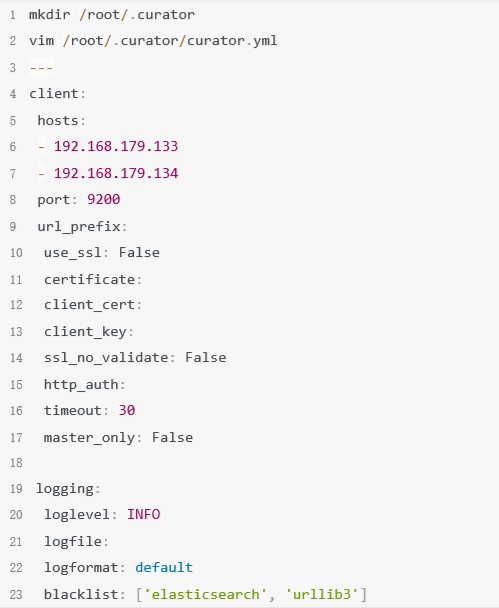
3.编辑action.yml,定义action
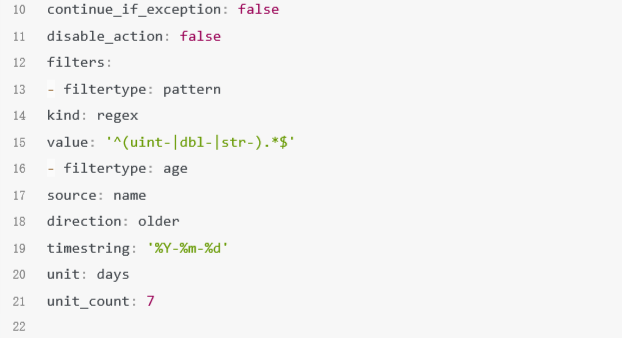
将7天以前的索引分配到冷节点

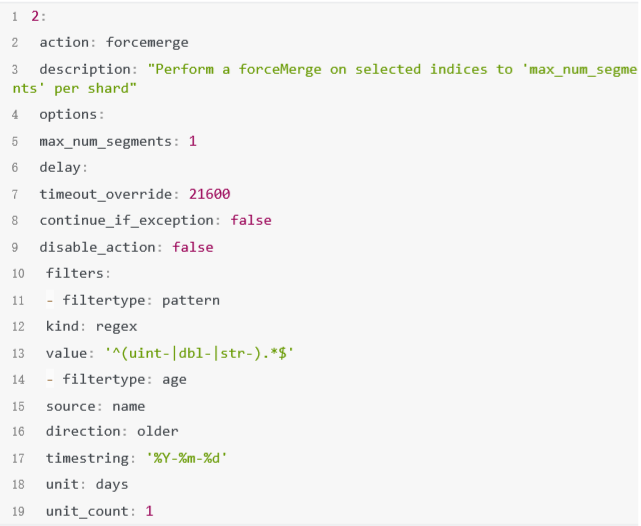
将前一天的索引强制合并,每个分片1个segment。
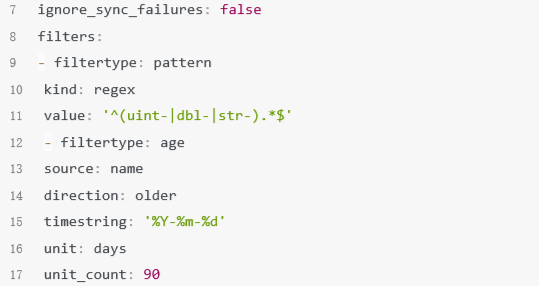
超过30天的索引将主分片数量修改为2,副本分片为0,执行shrink操作的节点不能作为 master节点


对超过三个月的索引进行关闭

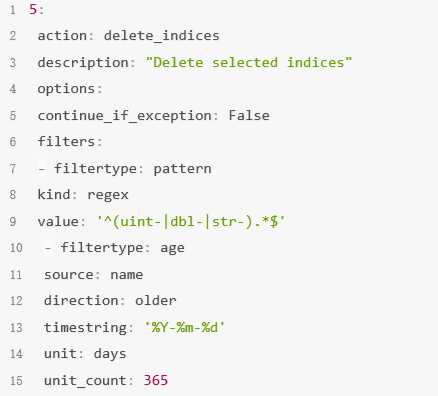
超过一年的索引进行删除
4.执行curator进行测试

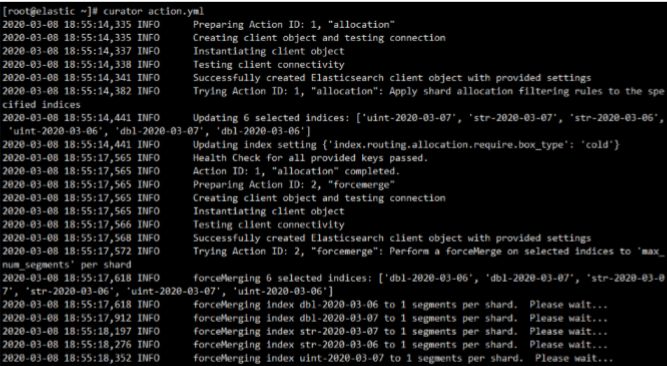
5. 将curator操作写进定时任务,每天执行

优化后的效果
▼
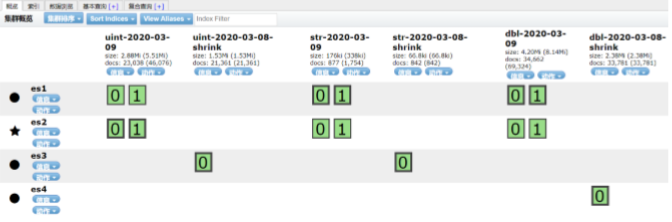
为了测试,这里我将curator执行的对象修改为一天以前的索引,并且shrink压缩成一个主 分片。可以看到前一天的分片已经迁移到冷节点上了,并且冷节点上只有一个主分片。
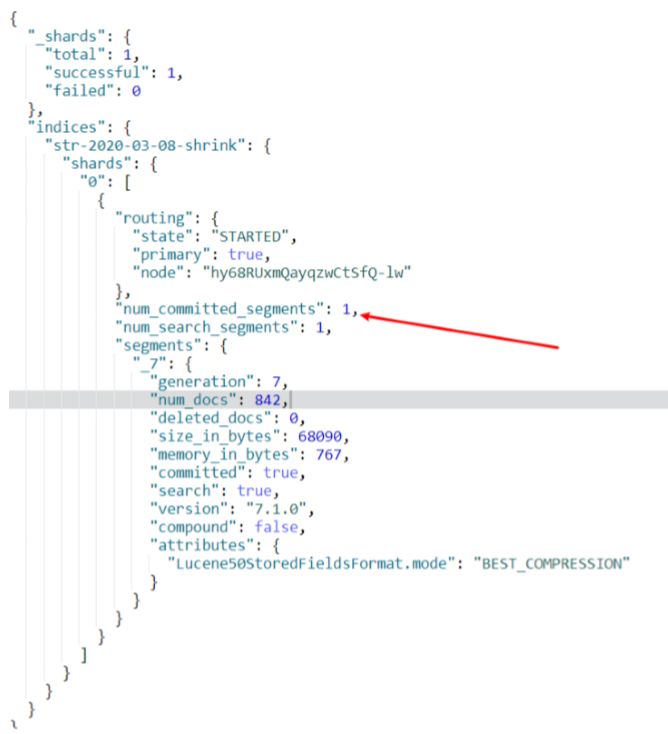
通过GET str-2020-03-08-shrink/_segments查看segment的数量,发现每个分片 segment的数量也只为1个。
至此,还请各路专家批评指正:)