提升资源利用率
1.1 资源浪费场景
- 资源预留普遍存在 50% 以上的浪费
Kubernetes 中的 Request(请求) 字段用于管理容器对 CPU 和内存资源预留的机制,保证容器至少可以达到的资源量,该部分资源不能被其他容器抢占,具体可查看。当 Request 设置过小,无法保证业务的资源量,当业务的负载变高时无力承载,因此用户通常习惯将 Request 设置得很高,以保证服务的可靠性。
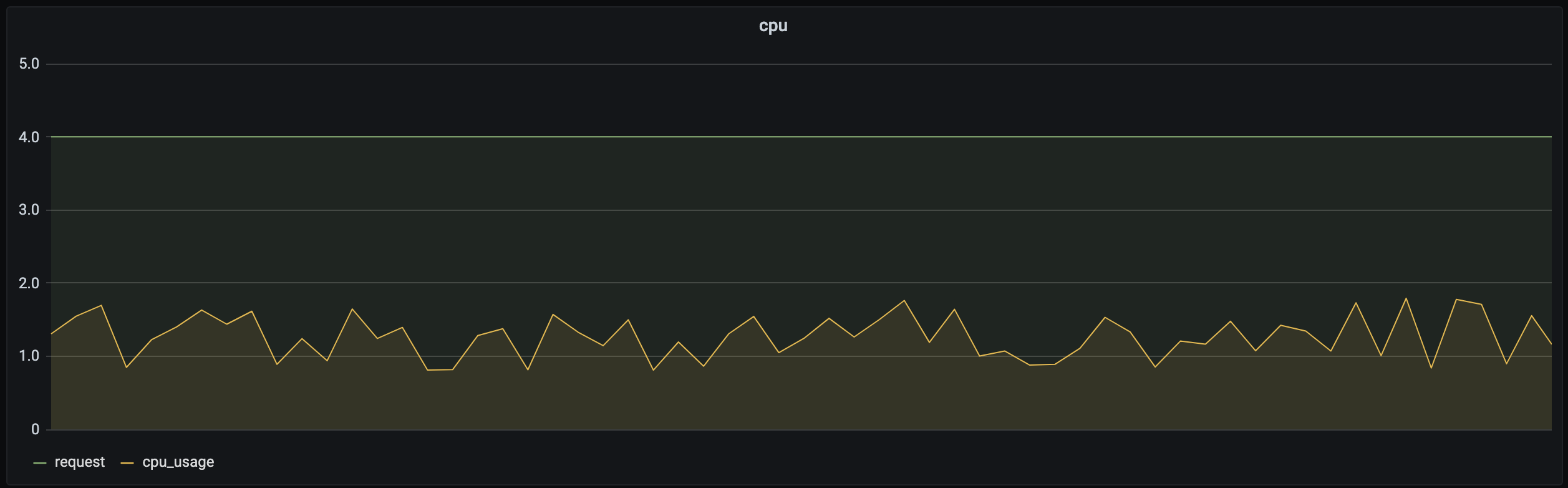
但实际上,业务在大多数时段时负载不会很高。以 CPU 为例,下图是某个实际业务场景下容器的资源预留(Request)和实际使用量(CPU_Usage)关系图:资源预留远大于实际使用量,两者之间差值所对应的资源不能被其他负载使用,因此 Request 设置过大势必会造成较大的资源浪费。
如何解决这样的问题?现阶段需要用户自己根据实际的负载情况设置更合理的 Request、以及限制业务对资源的无限请求,防止资源被某些业务过度占用。这里可以参考后文中的 Request Quota 和 Limit Ranges 的设置。
- 业务资源波峰波谷现象普遍,通常波谷时间大于波峰时间,资源浪费明显
大多数业务存在波峰波谷,例如公交系统通常在白天负载增加,夜晚负载减少;游戏业务通常在周五晚上开始出现波峰,在周日晚开始出现波谷。
如下图所示:同一业务在不同的时间段对资源的请求量不同,如果用户设置的是固定的 Request,业务在负载较低时利用率很低。
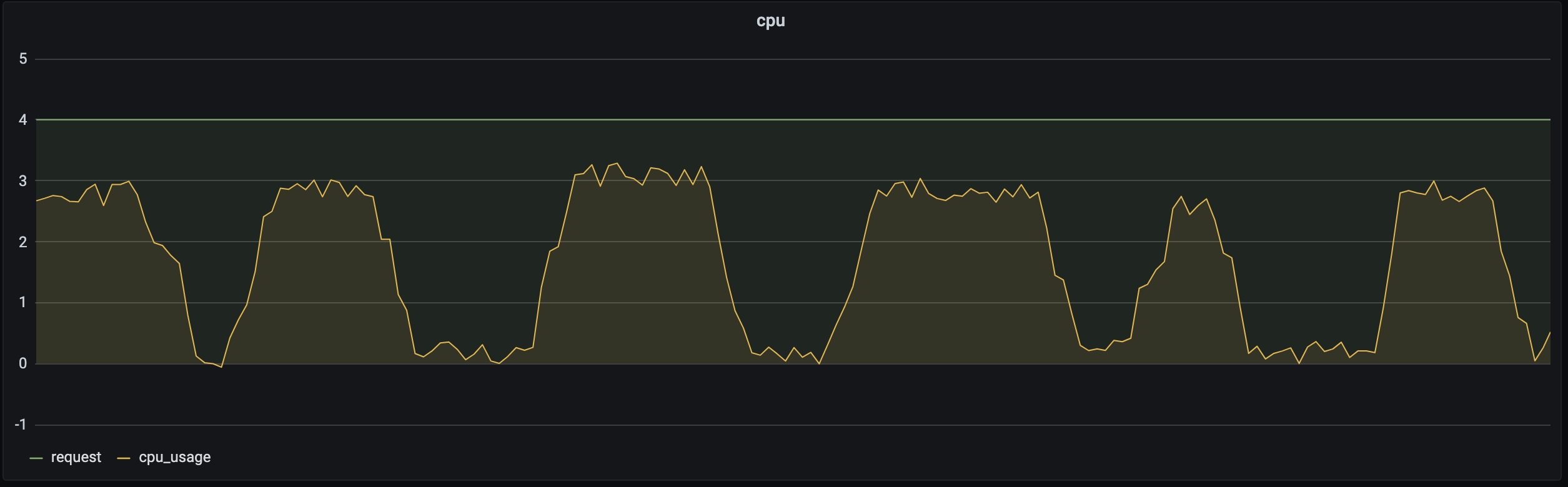
这时可以通过动态调整副本数,以高资源利用率承载业务的波峰波谷,可以参考
k8s原生提供的HPA 。
- 不同类型的业务,导致资源利用率有较大差异
在线业务通常白天负载较高,对时延要求较高,必须优先调度和运行;而离线的计算型业务通常对运行时段和时延要求相对较低,理论上可以在在线业务波谷时运行。此外,有些业务属于计算密集型,对 CPU 资源消耗较多,而有些业务属于内存密集型,对内存消耗较多。
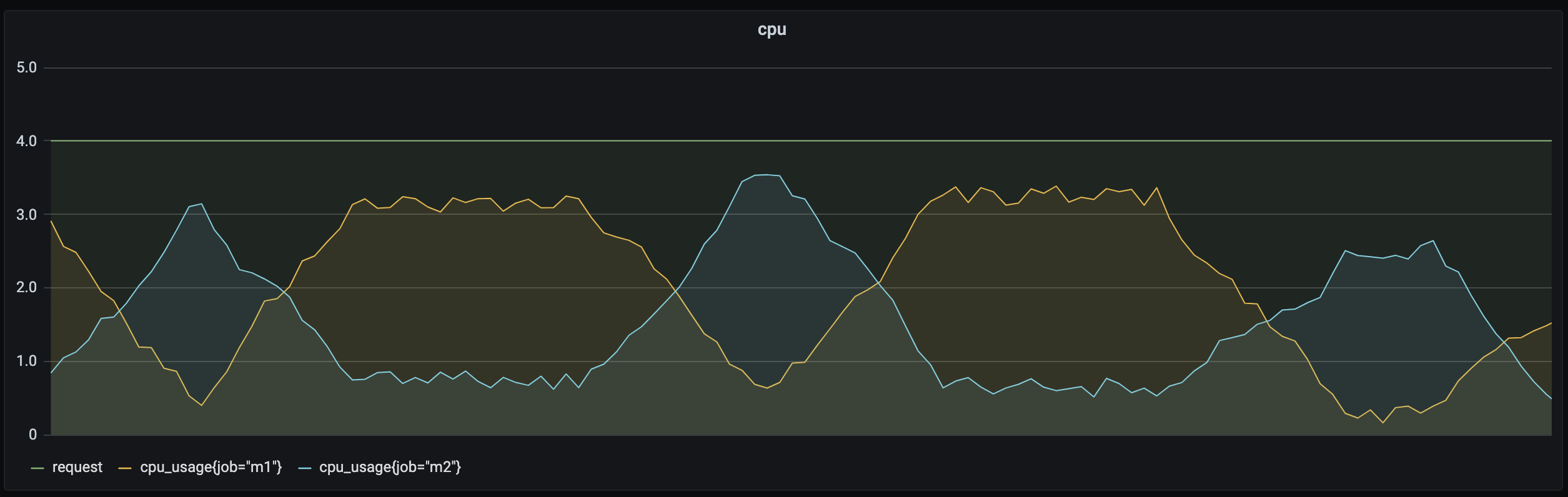
如上图所示,通过在离线混部可以动态调度离线业务和在线业务,让不同类型业务在不同的时间段运行以提升资源利用率。对于计算密集型业务和内存密集型业务,可以使用亲和性调度,为业务分配更合适的节点,以及通过taints/tolerations 策略隔离某些node给特定的业务场景使用,有效提升资源利用率。
1.2 提升资源利用率的方法
主要从两方面着手:一是利用原生的 Kubernetes 能力手动进行资源的划分和限制;二是结合业务特性的自动化方案。这里暂时介绍利用k8s原生能力进行资源的划分和限制。
1.2.1 如何资源划分和限制
设想,你是个集群管理员,现在有4个业务部门使用同一个集群,你的责任是保证业务稳定性的前提下,让业务真正做到资源的按需使用。为了有效提升集群整体的资源利用率,这时就需要限制各业务使用资源的上限,以及通过一些默认值防止业务过量使用。
理想情况下,业务应该根据实际情况,设置合理的 Request 和 Limit。(Request 用于对资源的占位,表示容器至少可以获得的资源;Limit 用于对资源的限制,表示容器至多可以获得的资源。)这样更利于容器的健康运行、资源的充分使用。但实际上用户经常忘记设置容器对资源的 Request 和 Limit。此外,对于共享使用一个集群的团队/项目来说,他们通常都将自己容器的 Request 和 Limit 设置得很高以保证自己服务的稳定性。
| Request | Limit | |
|---|---|---|
| CPU(核) | 0.25 | 0.5 |
| Memory(MiB) | 256 | 1024 |
为了更细粒度的划分和管理资源,可以设置命名空间级别的 Resource Quota 以及 Limit Ranges。
1.2.2 使用 Resource Quota 划分资源
如果你管理的某个集群有4个业务,为了实现业务间的隔离和资源的限制,你可以使用命名空间和 Resource Quota
Resource Quota 用于设置命名空间资源的使用配额,命名空间是 Kubernetes 集群里面的一个隔离分区,一个集群里面通常包含多个命名空间,例如 Kubernetes 用户通常会将不同的业务放在不同的命名空间里,你可以为不同的命名空间设置不同的 Resource Quota,以限制一个命名空间对集群整体资源的使用量,达到预分配和限制的效果。Resource Quota 主要作用于如下方面,具体可查看。
-
计算资源:所有容器对 CPU 和 内存的 Request 以及 Limit 的总和
-
存储资源:所有 PVC 的存储资源请求总和
-
对象数量:PVC/Service/Configmap/Deployment等资源对象数量的总和
Resource Quota 使用场景
- 给不同的项目/团队/业务分配不同的命名空间,通过设置每个命名空间资源的 Resource Quota 以达到资源分配的目的
- 设置一个命名空间的资源使用数量的上限以提高集群的稳定性,防止一个命名空间对资源的过度侵占和消耗
这里提供一个脚本,来为集群各命名空间设置初始的Resource Quota
「说明」:该脚本借助kubectl-view-allocations 插件获取集群各个命名空间当前所有pod所设置的request和limit总和,然后在此基础之上上浮30%用于设置命名空间的request和limit Resource Quota。
后续可通过集群具体情况,调整对应配置。
使用说明:
wget https://my-repo-1255440668.cos.ap-chengdu.myqcloud.com/ops/ResourceQuota-install.tar.gz
tar -xvf ResourceQuota-install.tar.gz
cd ResourceQuota-install && bash install.sh执行完之后,会在当前目录生成一个resourceQuota目录和limitrange目录,里面包含各个命名空间的ResourceQuota.yaml文件,便于后续根据集群实际情况,进行对应调整,调整之后再根据需要进行apply
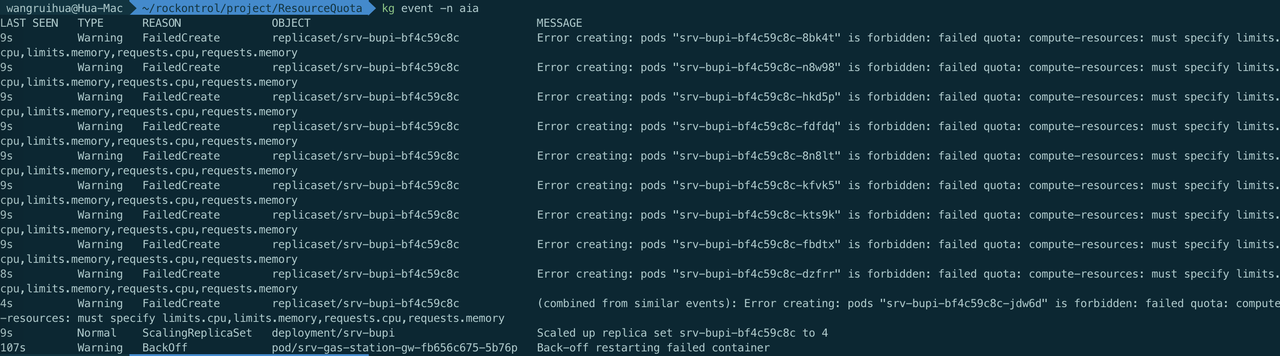
【注意】:如果命名空间request和limit总和超过了所设置的resourceQuota,那么将无法新建pod,而且设置了resourceQuota后,pod必须配置“limits.cpu,limits.memory,requests.cpu,requests.memory”,否则也无法正常部署,查看event会提示如下报错:
同时可通过监控查看该ns的的资源使用情况是否合理,调整原有各pod的request和limit,以及根据情况调整所设置的resourceQuota。
CI配置reques和limit的方式如下:
- yaml配置如下(其中resources字段):
【推荐配置】:
java服务:request和limit配置同样的值
golang/python服务: request和limit配置为1:2
#推荐配置:
#java服务:request和limit配置同样的值
#golang/python服务: request和limit配置为1:2
resources:
cpu: 500/1000m
memory: 500/1000Mi1.2.3 使用 Limit Ranges 限制资源
用户经常忘记设置资源的 Request 和 Limit,或者将值设置得很大怎么办?作为管理员,如果可以为不同的业务设置不同资源使用默认值以及范围,可以有效减少业务创建时的工作量同时,限制业务对资源的过度侵占。
与 Resource Quota 对命名空间整体的资源限制不同,Limit Ranges 适用于一个命名空间下的单个容器。可以防止用户在命名空间内创建对资源申请过小或过大容器,防止用户忘记设置容器的 Request 和 Limit。Limit Ranges 主要作用于如下方面,具体可查看。
-
计算资源:对所有容器设置 CPU 和内存使用量的范围
-
存储资源:对所有 PVC 能申请的存储空间的范围
-
比例设置:控制一种资源 Request 和 Limit 之间比例
-
默认值:对所有容器设置默认的 Request/Limit,如果容器未指定自己的内存请求和限制,将为它指定默认的内存请求和限制
Limit Ranges 使用场景
-
设置资源使用默认值,以防用户遗忘,也可以避免 QoS 驱逐重要的 Pod
-
不同的业务通常运行在不同的命名空间里,不同的业务通常资源使用情况不同,为不同的命名空间设置不同的 Request/Limit 可以提升资源利用率
-
限制容器个对资源使用的上下限,保证容器正常运行的情况下,限制其请求过多资源
1.2.4 调度策略
Kubernetes 调度机制是 Kubernetes 原生提供的一种高效优雅的资源分配机制,它的核心功能是为每个 Pod 找到最适合它的节点,通过合理利用 Kubernetes 提供的调度能力,根据业务特性配置合理的调度策略,也能有效提高集群中的资源利用率。
1.2.4.1 节点亲和性
- 说明
倘若你的某个业务是 CPU 密集型,不小心被 Kubernetes 的调度器调度到内存密集型的节点上,导致内存密集型的 CPU 被占满,但内存几乎没怎么用,会造成较大的资源浪费。如果你能为节点设置一个标记,表明这是一个 CPU 密集型的节点,然后在创建业务负载时也设置一个标记,表明这个负载是一个 CPU 密集型的负载,Kubernetes 的调度器会将这个负载调度到 CPU 密集型的节点上,这种寻找最合适的节点的方式,将有效提升资源利用率。
创建 Pod 时,可以设置节点亲和性,即指定 Pod 想要调度到哪些节点上(这些节点是通过 K8s Label)来指定的。
- 节点亲和性使用场景
节点亲和性非常适合在一个集群中有不同资源需求的工作负载同时运行的场景。比如说,k8s集群节点有 CPU 密集型的机器,也有内存密集型的机器。如果某些业务对 CPU 的需求远大于内存,此时使用普通的 节点 机器,势必会对内存造成较大浪费。此时可以在集群里添加一批 CPU 密集型的 节点,并且把这些对 CPU 有较高需求的 Pod 调度到这些 节点上,这样可以提升 节点 资源的整体利用率。同理,还可以在集群中管理异构节点(比如 GPU 机器),在需要 GPU 资源的工作负载中指定需要GPU资源的量,调度机制则会帮助你寻找合适的节点去运行这些工作负载。
1.2.4.2 Taints和Tolerations(污点和容忍)
- 说明
我们说到的的NodeAffinity节点亲和性,是在pod上定义的一种属性,使得Pod能够被调度到某些node上运行。Taint刚好相反,它让Node拒绝Pod的运行。
Taint需要与Toleration配合使用,让pod避开那些不合适的node。在node上设置一个或多个Taint后,除非pod明确声明能够容忍这些“污点”,否则无法在这些node上运行。Toleration是pod的属性,让pod能够(注意,只是能够,而非必须)运行在标注了Taint的node上。
创建 Pod 时,可以通过设置Taints和Tolerations,来让某些node只允许某些特定的pod
- Taints和Tolerations场景
-
节点独占。
如果想要拿出一部分节点,专门给特定的应用使用,则可以为节点添加这样的Taint:
kubectl taint nodes nodename dedicated=groupName:NoSchedule然后给这些应用的pod加入相应的toleration,则带有合适toleration的pod就会被允许同使用其他节点 一样使用有taint的节点。然后再将这些node打上指定的标签,再通过nodeSelector或者亲和性调度的方式,要求这些pod必须运行在指定标签的节点上。
- 具有特殊硬件设备的节点
在集群里,可能有一小部分节点安装了特殊的硬件设备,比如GPU芯片。用户自然会希望把不需要占用这类硬件的pod排除在外。以确保对这类硬件有需求的pod能够顺利调度到这些节点上。可以使用下面的命令为节点设置taint:
kubectl taint nodes nodename special=true:NoSchedule
kubectl taint nodes nodename special=true:PreferNoSchedule然后在pod中利用对应的toleration来保障特定的pod能够使用特定的硬件。然后同样的,我们也可以使用标签或者其他的一些特征来判断这些pod,将其调度到这些特定硬件的服务器上
- 应对节点故障
在节点故障时,可以通过TaintBasedEvictions功能自动将节点设置Taint,然后将pod驱逐。但是在一些场景下,比如说网络故障造成的master与node失联,而这个node上运行了很多本地状态的应用即使网络故障,也仍然希望能够持续在该节点上运行,期望网络能够快速恢复,从而避免从这个node上被驱逐。Pod的Toleration可以这样定义:
tolerations:
- key: "node.alpha.kubernetes.io/unreachable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 6000未完待续。。。