随着Kubernetes的不断发展,技术不断成熟,越来越多的公司选择把自家的应用部署到Kubernetes中。但是把应用部署到Kubernetes中就完事了吗?显然不是,应用容器化只是万里长征的第一步,如何让应用安心、稳定的运行才是后续的所有工作。
这里主要从一下几个方面来进行整理,对于大部分公司足够使用。
Node
Node可以是物理主机,也可以是云主机,它是Kubernetes的载体。在很多时候我们并不太关心Node怎么样了,除非其异常。但是作为运维人员,我们最不希望的就是异常,对于Node也是一样。
Node节点并不需要做太多太复杂的操作,主要如下:
内核升级
对于大部分企业,CentOS系统还是首选,默认情况下,7系列系统默认版本是3.10,该版本的内核在Kubernetes社区有很多已知的Bug,所以对节点来说,升级内核是必须的,或者企业可以选择Ubuntu作为底层操作系统。
升级内核的步骤如下(简单的升级方式):
wget https://elrepo.org/linux/kernel/el7/x86_64/RPMS/kernel-lt-5.4.86-1.el7.elrepo.x86_64.rpm
rpm -ivh kernel-lt-5.4.86-1.el7.elrepo.x86_64.rpm
cat /boot/grub2/grub.cfg | grep menuentry
grub2-set-default 'CentOS Linux (5.4.86-1.el7.elrepo.x86_64) 7 (Core)'
grub2-editenv list
grub2-mkconfig -o /boot/grub2/grub.cfg
reboot
软件更新
对于大部分人来说,更新软件在很多情况下是不做的,因为害怕兼容问题。不过在实际生产中,对于已知有高危漏洞的软件,我们还需要对其进行更新,这个可以针对处理。优化Docker配置文件
对于Docker的配置文件,主要优化的就是日志驱动、保留日志大小以及镜像加速等,其他的配置根据情况而定,如下:
cat > /etc/docker/daemon.json << EOF
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m",
"max-file": "10"
},
"bip": "169.254.123.1/24",
"oom-score-adjust": -1000,
"registry-mirrors": ["https://pqbap4ya.mirror.aliyuncs.com"],
"storage-driver": "overlay2",
"storage-opts":["overlay2.override_kernel_check=true"],
"live-restore": true
}
EOF优化kubelet参数
对于K8S来讲,kubelet是每个Node的组长,负责Node的"饮食起居",这里对它的参数配置主要如下:
cat > /etc/systemd/system/kubelet.service <<EOF
[Unit]
Description=kubelet: The Kubernetes Node Agent
Documentation=https://kubernetes.io/docs/
[Service]
ExecStartPre=/usr/bin/mkdir -p /sys/fs/cgroup/pids/system.slice/kubelet.service
ExecStartPre=/usr/bin/mkdir -p /sys/fs/cgroup/cpu/system.slice/kubelet.service
ExecStartPre=/usr/bin/mkdir -p /sys/fs/cgroup/cpuacct/system.slice/kubelet.service
ExecStartPre=/usr/bin/mkdir -p /sys/fs/cgroup/cpuset/system.slice/kubelet.service
ExecStartPre=/usr/bin/mkdir -p /sys/fs/cgroup/memory/system.slice/kubelet.service
ExecStartPre=/usr/bin/mkdir -p /sys/fs/cgroup/systemd/system.slice/kubelet.service
ExecStart=/usr/bin/kubelet \
--enforce-node-allocatable=pods,kube-reserved \
--kube-reserved-cgroup=/system.slice/kubelet.service \
--kube-reserved=cpu=200m,memory=250Mi \
--eviction-hard=memory.available<5%,nodefs.available<10%,imagefs.available<10% \
--eviction-soft=memory.available<10%,nodefs.available<15%,imagefs.available<15% \
--eviction-soft-grace-period=memory.available=2m,nodefs.available=2m,imagefs.available=2m \
--eviction-max-pod-grace-period=30 \
--eviction-minimum-reclaim=memory.available=0Mi,nodefs.available=500Mi,imagefs.available=500Mi
Restart=always
StartLimitInterval=0
RestartSec=10
[Install]
WantedBy=multi-user.target
EOF
其功能主要是为每个Node增加资源预留,可以在一定程度上防止Node宕机。
日志配置管理
这里的日志配置管理针对的是系统日志,非自研应用日志。默认情况下,系统日志都不需要我们特殊配置,我这里提出来,主要是保障日志的可追溯。当系统因为某种原因被入侵,系统系统被删除的情况下,还有日志提供给我们分析。
所以在条件允许的情况下,对Node节点的系统日志进行远程备份是有必要的,可以采用rsyslog进行配置管理,日志可以保存到远端的日志中心或者oss上。
安全配置
安全配置这里涉及的不多,主要是针对已知的一些安全问题进行加固。主要有以下五种(当然还有更多,看自己的情况):
● ssh密码过期策略
● 密码复杂度策略
● ssh登录次数限制
● 系统超时配置
● 历史记录配置
Pod
Pod是K8S的最小调度单元,是应用的载体,它的稳定直接关乎应用本身,在部署应用的时候,主要考虑一下几个方面。
资源限制
Pod使用的是主机的资源,合理的资源限制可以有效避免资源超卖或者资源抢占问题。在配置资源限制的时候,要根据实际的应用情况来决定Pod的QoS,不同的QoS配置情况不一样。
如果应用的级别比较高,建议配置Guaranteed级别配置,如下:
resources:
limits:
memory: "200Mi"
cpu: "700m"
requests:
memory: "200Mi"
cpu: "700m"
如果应用级别一般,建议配置Burstable级别,如下:
resources:
limits:
memory: "200Mi"
cpu: "500m"
requests:
memory: "100Mi"
cpu: "100m"
强烈不建议使用BestEffort类型的Pod。
调度策略
调度策略也是根据情况来定,如果你的应用需要指定调度到某些节点,可以使用亲和性调度,如下:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- preference: {}
weight: 100
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:- matchExpressions:
- key: env
operator: In
values:- uat
如果一个节点只允许某一个应用调度,这时候就需要用到污点调度了,也就是先给节点打污点,然后需要调度到该节点的Pod需要容忍污点。最稳妥的方式是标签+污点相结合。如下:
tolerations:- key: "key1" #能容忍的污点key
operator: "Equal" #Equal等于表示key=value , Exists不等于,表示当值不等于下面value正常
value: "value1" #值
effect: "NoExecute" #effect策略
tolerationSeconds: 3600 #原始的pod多久驱逐,注意只有effect: "NoExecute"才能设置,不然报错
当然,除了Pod和Node的关联,还有Pod和Pod之间的关联,一般情况下,为了达到真正的高可用,我们不建议同一个应用的Pod都可以调度到同一个节点,所以我们需要给Pod做反亲和性调度,如下:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:
matchExpressions:- key: app
operator: In
values:- store
topologyKey: "kubernetes.io/hostname"
如果某个应用亲和其他应用,则可以使用亲和性,这样可以在一定程度上降低网络延迟,如下:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:
matchExpressions:- key: security
operator: In
values:- S1
topologyKey: failure-domain.beta.kubernetes.io/zone
优雅升级
Pod默认是采用的滚动更新策略,我们关注点主要在新的Pod起来后,老的Pod如何能优雅的处理流量,对外界是无感的。
最简单的方式是"睡几秒",这种方式并不能保证百分百的优雅处理流量,方式如下:
lifecycle:
preStop:
exec:
command:
- /bin/sh
- -c
- sleep 15
如果有注册中心,可以在退出的时候先把原服务从注册中心下线再退出,比如这里使用的nacos作为注册中心,如下:
lifecycle:
preStop:
exec:
command:
- /bin/sh
- -c
- "curl -X DELETE your_nacos_ip:8848/nacos/v1/ns/instance?serviceName=nacos.test.1&ip=${POD_IP}&port=8880&clusterName=DEFAULT" && sleep 15
探针配置
探针重要吗?重要!它是kubelet判断Pod是否健康的重要依据。
Pod的主要探针有:
● livenessProbe
● readinessProbe
● startupProbe
其中startupProbe是v1.16版本后才新增的探针,其主要针对启动时间较长的应用,在多数情况下只需要配置livenessProbe和readinessProbe即可。
通常情况下,一个Pod就代表一个应用,所以在配置探针的时候最好能直接反应应用是否正常,很多框架都带有健康检测功能,我们在配置探针的时候可以考虑使用这些健康检测功能,如果框架没有,也可以考虑让开发人员统一开发一个健康检测接口,这样便于标准化健康检测。如下:
readinessProbe:
failureThreshold: 3
httpGet:
path: /health
port: http
scheme: HTTP
initialDelaySeconds: 40
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 3
livenessProbe:
failureThreshold: 3
httpGet:
path: /health
port: http
scheme: HTTP
initialDelaySeconds: 60
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 2
如果需要配置startupProbe,则可以如下配置:
startupProbe:
httpGet:
path: /health
prot: 80
failureThreshold: 10
initialDelay:10
periodSeconds: 10
保护策略
这里的保护策略主要是指在我们主动销毁Pod的时候,通过保护策略来控制Pod的运行个数。
在K8S众通过PodDisruptionBudget(PDB)来实现这个功能,对于一些重要应用,我们需要为其配置PDB,如下:
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: pdb-demo
spec:
minAvailable: 2
selector:
matchLables:
app: nginx
在PDB中,主要通过两个参数来控制Pod的数量:
● minAvailable:表示最小可用Pod数,表示在Pod集群中处于运行状态的最小Pod数或者是运行状态的Pod数和总数的百分比;
● maxUnavailable:表示最大不可用Pod数,表示Pod集群中处于不可用状态的最大Pod数或者不可用状态Pod数和总数的百分比;
注意:minAvailable和maxUnavailable是互斥了,也就是说两者同一时刻只能出现一种。
日志
日志会贯穿应用的整个生命周期,在排查问题或者分析数据的时候,日志都不可缺少。对于日志,这里主要从以下方面进行分析。
日志标准
日志一般分为业务日志和异常日志,对于日志,我们不希望其太复杂,也不希望其太简单,更多的是希望通过日志达到如下目标:
- 对程序运行情况的记录和监控;
- 在必要时可详细了解程序内部的运行状态;
- 对系统性能的影响尽量小;
那日志标准如何定义呢?我这里简单整理以下几点:
● 合理使用日志分级
● 统一输出格式
● 代码编码规范
● 日志输出路径统一
● 日志输出命名规范统一
这样规定的主要目的是便于收集和查看日志。
收集
针对不同的日志输出有不同的日志收集方案,主要有以下二种:
● 在Node上部署Logging Agent进行收集
● 在Pod中以Sidecar形式进行收集
在Node上部署Logging Agent进行收集
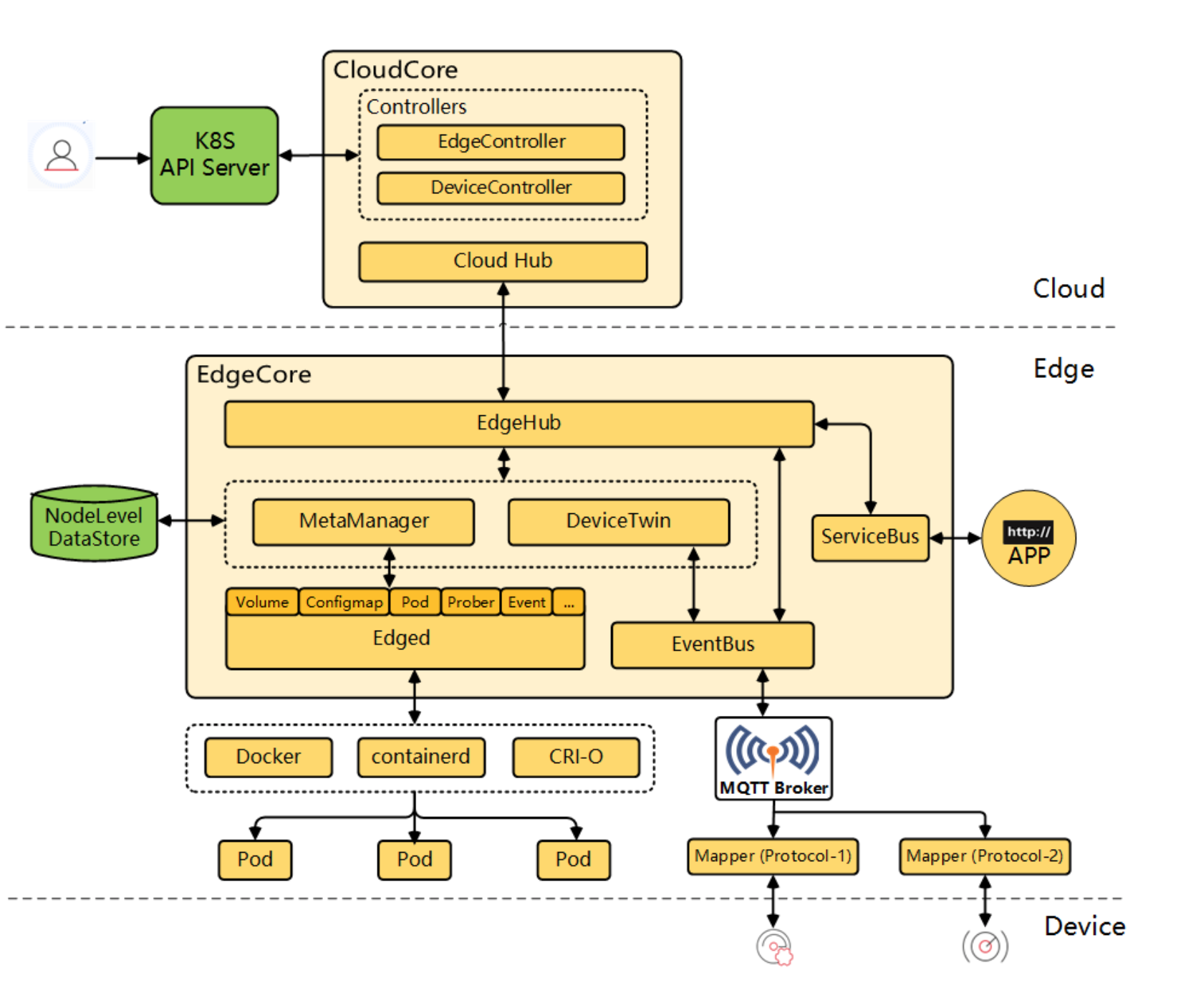
这种日志收集方案主要针对已经标准输出的日志,架构如下:
对于非标准输出的日志就没办法进行收集。
在Pod中以Sidecar形式进行收集
这种收集方案主要针对非标准输出的日志,可以在Pod中以sidecar的方式运行日志收集客户端,将日志收集到日志中心,架构如下:
不过这种方式比较浪费资源,所以最理想的情况就是把应用日志都标准输出,这样收集起来比较简单。
分析
在业务正常的情况下,我们其实很少去查看日志内容,只有在出问题的时候才会借助日志分析问题(大部分情况下都是这样),那为什么我这里要把分析提出来呢?
日志其实承载了很多信息,如果能对日志进行有效分析,可以帮助我们识别、排查很多问题,比如阿里云的日志中心,在日志分析方面做的就很不错。
告警
日志告警,可以让我们快速知道问题,也缩小了故障排查范围。不过要做日志告警就必须做好日志“关键字”管理,也就是要确定某一个关键字能够准确的代表一个问题,最好不出现泛指的现象,这样做的好处就是能够让告警更加准备,而不是出现一些告警风暴或者无效告警,久而久之就麻木了。
监控
集群、应用等的生命周期里离不开监控系统,有效的监控系统可以为我们提供更高的可观测性,方便我们线性的分析问题,排查问题以及定位问题,再配上有效的告警通知,也方便我们能快速的知道问题。
对于监控,主要从一下几个方面进行介绍。
集群监控
对于K8S集群以及跑在K8S应用来说,普遍使用Prometheus来进行监控。整个集群的稳定性关乎着应用的稳定性,所以对集群的监控至关重要,下面简单列举了一些监控项,在实际的工作中酌情处理。应用监控
在很多企业中,并没有接入应用监控,主要还是没有在应用中集成监控指标,导致无法监控,所以在应用开发的时候就强烈建议开发将应用监控加上,将指标按prometheus标准格式暴露出来。
除了开发人员主动暴露指标外,我们也可以通过javaagent方式配置一些exporter,用来抓取一些指标,比如jvm监控指标。
在应用级别做监控,可以将监控粒度更细化,这样可以更容易发现问题。我这里简单整理了一些应用监控项,如下:
这些监控项都有对于的exporter来完成,比如redis中间件有redis-exporter,api监控有blcakbox-exporter等。
事件监控
在Kubernetes中,事件分为两种,一种是Warning事件,表示产生这个事件的状态转换是在非预期的状态之间产生的;另外一种是Normal事件,表示期望到达的状态,和目前达到的状态是一致的。
事件大多数情况下表示正在发生或者已经发生的事,在实际工作中很容易就忽略这类信息,所以我们有必要借助事件监控来规避这类问题。
在K8S中,常用的事件监控是kube-eventer,它可以收集pod/node/kubelet等资源对象的event,还可以收集自定义资源对象的event,然后将这类信息发送到相关人员。
通过事件,我们主要关注的监控项如下:
链路监控
正常情况下,K8S中的应用是单独的个体存在,彼此之间没有显性的联系,这时候就需要一种手段,将应用间的关系表现出来,方便我们跟踪分析整个链路的问题。
目前比较流行的链路监控工具有很多,我这边主要是使用skywalking进行链路监控,其主要agent端比较丰富,也提供了很高的自扩展能力,有兴趣的朋友可以了解一下。
通过链路监控,主要达到以下目的。
告警通知
很多人会忽略告警通知,觉得告警就行。但是在做告警通知的时候还是需要仔细去考虑的。
如下简单整理一下关注点。
个人觉得难点在于哪些指标需要告警。我们在选取指标的时候一定要遵循以下规则:
● 告警的指标具有唯一性
● 告警的指标能正确反应问题
● 所暴露的问题是需要借入解决的
综合这些规则考虑,才方便我们选取需要的指标。
第二就是紧急程度分类,这个主要是根据这个告警指标所暴露出来的问题是不是需要我们及时去解决,还有影响范围来综合衡量。
故障升级主要是针对需要解决的问题没有解决而做的一种策略,提高故障等级,也相当于提高了紧急程度了。通知渠道分类主要是方便我们区分不同的告警,还有如果能快速接收到告警信息。
写在最后
上面写的都是一些基础的操作,对于YAML工程师来说,算是必备的技能储备,这一套放到大部分公司都是适用的。
如果有写错的地方或者更好的建议,欢迎留言交流,也可以加群进行交流。