人活在世上,什么都不要怕,做自己认为对的事儿,慢慢放下输赢和计算。
——冯唐
关于Elastic Stack
elasticstack是一个应用套件,原名为ELK Stack,由elastic旗下的elasticsearch、logstash、kibana,filebeat四个组件组成,这四个工具组合形成了一套实用、易用的监控架构,很多公司利用它来搭建可视化的海量日志分析平台。
Elasticsearch简介
Elasticsearch是一个高度可扩展的开源全文搜索和分析引擎。它允许您快速,近实时地存储,搜索和分析大量数据。它通常用作底层引擎/技术,为具有复杂搜索功能和要求的应用程序提供支持。
Logstash简介
logstash是一款轻量级的用于收集,丰富和统一所有数据的开源日志收集引擎,个人理解logstash就像一根管道,有输入的一端,有输出的一端,管道内存在着过滤装置,可以将收集的日志转换成我们想要看到的日志,输入的一端负责收集日志,管道输出的一端会将日志输出到你想要存放的位置,大多数是输出到elasticsearch里面
Kibana简介
Kibana是一个开源分析和可视化平台,旨在与Elasticsearch协同工作。可以轻松地执行高级数据分析,并在各种图表,表格和地图中可视化您的数据。Kibana使您可以轻松理解大量数据。其简单的基于浏览器的界面使您能够快速创建和共享动态仪表板,实时显示Elasticsearch查询的更改。
Filebeat简介
Filebeat是属于Beats系列的日志托运者 - 一组安装在主机上的轻量级托运人,用于将不同类型的数据传送到ELK堆栈进行分析。每个节拍专门用于传送不同类型的信息 - 例如,Winlogbeat发布Windows事件日志,Metricbeat发布主机指标等等。顾名思义,Filebeat提供日志文件。
在基于ELK的日志记录管道中,Filebeat扮演日志代理的角色 - 安装在生成日志文件的计算机上,并将数据转发到Logstash以进行更高级的处理,或者直接转发到Elasticsearch进行索引。因此,Filebeat不是Logstash的替代品,但在大多数情况下可以并且应该同时使用。
Elastic Stack安装配置
Logstash安装
1.安装logstash需要依赖Java8的环境,不支持Java9
使用yuminstall java命令安装
2.下载并安装公共签名密钥
rpm --importhttps://artifacts.elastic.co/GPG-KEY-elasticsearch
3.添加logstash的yum仓库
vim/etc/yum.repos.d/logstash.repo
[logstash-6.x] name=Elastic repository for 6.xpackages baseurl=https://artifacts.elastic.co/packages/6.x/yum gpgcheck=1gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1autorefresh=1 type=rpm-md
4.使用yuminstall logstash命令安装logstash
Elasticsearch安装
elasticsearch同样需要Java运行环境
1.下载elasticsearch的tar包
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.4.0.tar.gz
2.解压包
tar -xzfelasticsearch-6.4.0.tar.gz
3.修改配置文件
[root@elasticelasticsearch-6.4.0]# vim config/elasticsearch.yml
修改内容如下:
cluster.name:my-elk #设置集群的名字
node.name:es1 #集群中的节点名称,同一集群中的节点名称不能重复
path.data:/elasticsearch/elasticsearch-6.4.0/data #设置es集群的数据位置
path.logs:/elasticsearch/elasticsearch-6.4.0/logs/ #设置存放日志的路径
network.host:192.168.179.134 #绑定本地ip地址
http.port:9200 #设置开放的端口,默认就是9200端口
4.启动elasticsearch
cdelasticsearch-6.4.0/
./bin/elasticsearch
这里要使用普通用户运行,还要把目录授予普通文件权限
chown -Relker.elker /elasticsearch
5.查看启动状态
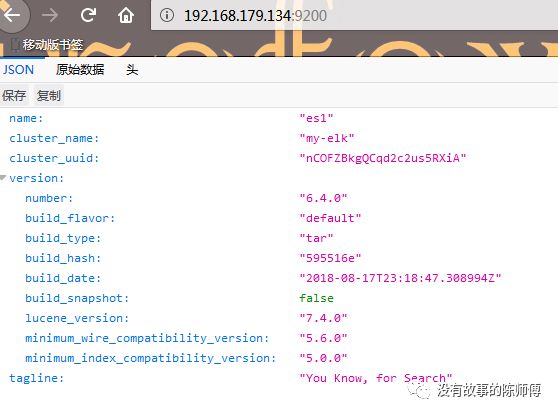
输入netstat -ntlp|grep 9200查看9200端口是否监听,可以使用curl192.168.179.134:9200或者在浏览器上输入192.168.179.134:9200进行查看启动后的状态
5.启动过程出现的报错
[WARN][o.e.b.BootstrapChecks ] [PWm-Blt]max file descriptors [4096] for elasticsearch process is too low, increase toat least [65536]
解决办法:
vim/etc/security/limits.conf
* softnofile 65536
* hardnofile 131072
* soft nproc2048
* hard nproc4096
[WARN][o.e.b.BootstrapChecks ] [PWm-Blt]max virtual memory areas vm.max_map_count [65530] is too low, increase to atleast [262144]
解决办法:
vim/etc/sysctl.conf
vm.max_map_count=655360
修改完成执行命令:
sysctl-p
Elasticsearch Head插件安装
对elasticsearch集群的操作一直通过rest请求是比较麻烦的,elasticsearch提供了一个head插件来对elasticsearch集群在浏览器上进行操作,ElasticSearch-head是一个H5编写的ElasticSearch集群操作和管理工具,可以对集群进行傻瓜式操作。下面我们来进行head插件的安装。
1.安装node.js
这里我采用的源码安装,其实二进制安装是比较简单的,但我执行到最后node的二进制文件无法执行,因此只能源码安装,时间有点长,打了两局王者荣耀才装完
wget https://nodejs.org/dist/v8.11.4/node-v8.11.4.tar.gz #下载node的源码包
tar -zxvfnode-v8.11.4 #解压源码包
./configure && make && make install #执行编译安装
echo $? #查看执行结果,输出0表示安装成功
node.js默认安装路径在/usr/local/bin/目录下
2.安装grunt
grunt是基于Node.js的项目构建工具,可以进行打包压缩、测试、执行等等的工作,head插件就是通过grunt启动
npm install -g grunt-cli
3.下载并安装head插件
git clonegit://github.com/mobz/elasticsearch-head.git #克隆head插件仓库
cd elasticsearch-head/
npm install #执行完会报一些错误,不要管执行下一条命令就会解决
npm install phantomjs-prebuilt@2.1.14 --ignore-scripts
4.修改elasticsearch的配置
vim/elasticsearch/elasticsearch-6.4.0/config/elasticsearch.yml
http.cors.enabled: true #elasticsearch中启用CORShttp.cors.allow-origin: "*" # 允许访问的IP地址段,* 为所有IP都可以访问
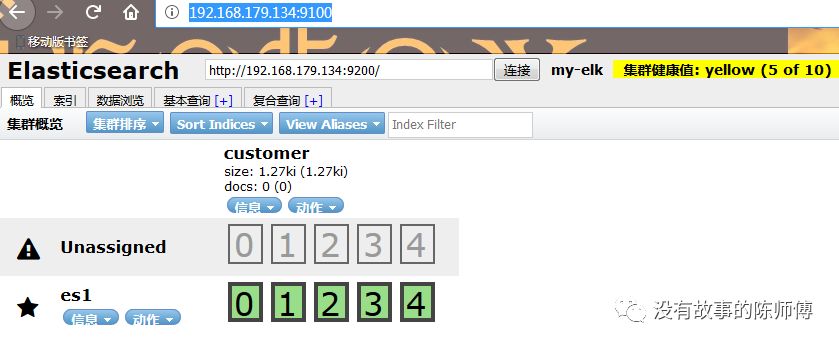
5.启用head插件并在浏览器上打开
npm run start #启动head插件
在浏览器输入http://192.168.179.134:9100/即可使用head插件
在以后的每次启动中,只需要在head插件的目录执行grunt server就可以了
Kibana安装
1.下载并解压kibana包
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.4.0-linux-x86_64.tar.gz
tar -xzfkibana-6.4.0-linux-x86_64.tar.gz
2.修改kibana默认配置
vimkibana-6.4.0-linux-x86_64/config/kibana.yml
server.port:5601 #kibana默认端口是5601
server.host:"192.168.179.134" #设置绑定的kibana服务的地址
elasticsearch.url:"http://192.168.179.134:9200" #设置elasticsearch服务器的ip地址,不修改的话启动的时候会报[elasticsearch] Unable to revive connection: http://localhost:9200/连接不上elasticsearch的错误
kibana.index:".kibana" #创建一个kibana的索引
3.启动kibana
/kibana-6.4.0-linux-x86_64/bin/kibana
netstat-ntlp |grep 5601 #可以查看5601端口是否启动
在浏览器输入192.168.179.134:5601即可访问kibana
4.出现的警告信息
虽然出现警告信息,不过还是可以启动kibana的,本人有点强迫症,不想看到警告信息
警告信息1:[security] Generating a random key for xpack.security.encryptionKey.To prevent sessions from being invalidated on restart, please setxpack.security.encryptionKey in kibana.yml
解决方法:修改配置文件vimconfig/kibana.yml
在配置文件底部添加
xpack.reporting.encryptionKey:"a_random_string"
警告信息2:[security] Session cookies will be transmitted over insecureconnections. This is not recommended.
解决方法:修改配置文件vimconfig/kibana.yml
在配置文件底部添加
xpack.security.encryptionKey:"something_at_least_32_characters"
5.检查kibana状态
在浏览器输入192.168.179.134:5601/status查看kibana状态,或者输入http://192.168.179.134:5601/api/status查看json格式的详细状态
Elasticsearch的相关概念与操作
集群
集群是一个或多个节点(服务器)的集合,它们共同保存您的整个数据,并提供跨所有节点的联合索引和搜索功能。
集群健康
Elasticsearch 的集群监控信息中包含了许多的统计数据,其中最为重要的一项就是集群健康,它在status字段中展示为 green 、yellow或者red 。
它的三种颜色含义如下:
green
所有的主分片和副本分片都正常运行。
yellow
所有的主分片都正常运行,但不是所有的副本分片都正常运行。
red
有主分片没能正常运行。
可以在命令行使用curl -X GET"192.168.179.134:9200/_cluster/health"
或者在浏览器上输入192.168.179.134:9200/_cluster/health查看集群健康状态
“unassigned_shards”表示没有分配到任何节点上的副本分片数
节点
节点是作为群集一部分的单个服务器,存储数据并参与群集的索引和搜索功能。一个运行中的Elasticsearch 实例称为一个 节点,而集群是由一个或者多个拥有相同集群名配置的节点组成,它们共同承担数据和负载的压力。当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据。
当一个节点被选举成为 主节点时, 它将负责管理集群范围内的所有变更,例如增加、删除索引,或者增加、删除节点等。而主节点并不需要涉及到文档级别的变更和搜索等操作,作为用户,我们可以将请求发送到集群中的任何节点,包括主节点。每个节点都知道任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点。无论我们将请求发送到哪个节点,它都能负责从各个包含我们所需文档的节点收集回数据,也就是说,你发送的请求发到了整个elasticsearch集群上
索引
索引是具有某些类似特征的文档集合。例如,如果你要收集系统日志,你可以建立一个系统日志的索引。 索引实际上是指向一个或者多个物理分片的逻辑命名空间 。
分片
一个分片是一个底层的工作单元,它仅保存了全部数据中的一部分。 Elasticsearch是利用分片将数据分发到集群内各处的。分片是数据的容器,文档保存在分片内,分片又被分配到集群内的各个节点里。当你的集群规模扩大或者缩小时, Elasticsearch 会自动的在各节点中迁移分片,使得数据仍然均匀分布在集群里。每个分片本身都是一个功能齐全且独立的“索引”,可以托管在集群中的任何节点上。一个分片可以是主分片或者副本分片。 索引内任意一个文档都归属于一个主分片,所以主分片的数目决定着索引能够保存的最大数据量。一个副本分片只是一个主分片的拷贝。 副本分片作为硬件故障时保护数据不丢失的冗余备份,并为搜索和返回文档等读操作提供服务。在索引建立的时候就已经确定了主分片数,但是副本分片数可以随时修改。
在相同节点数目的集群上增加更多的副本分片并不能提高性能,因为每个分片从节点上获得的资源会变少。但是更多的副本分片数提高了数据冗余量。
索引与分片的比较
被混淆的概念是,一个 Lucene 索引 我们在 Elasticsearch 称作分片。一个elasticsearch索引是分片的集合。当 Elasticsearch 在索引中搜索的时候, 他发送查询到每一个属于索引的分片(Lucene 索引),然后像 执行分布式检索 提到的那样,合并每个分片的结果到一个全局的结果集。
创建索引
在命令行中执行curl-X PUT "192.168.179.134:9200/custome?pretty"可以创建一个名为custome的索引,如果要修改索引创建默认的主分片数和副本分片数,可以执行如下命令
[root@elastic~]# curl -X PUT "192.168.179.134:9200/blogs" -H 'Content-Type:application/json' -d'
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
'
以上命令表示创建了一个包含3个主分片和一个副本(即三个副本分片)的blogs索引
我们还可以在浏览器使用http://192.168.179.134:9200/_cat/indices?v或者在命令行中使用curl -X GET "http://192.168.179.134:9200/_cat/indices?v"查看集群中的索引

可以看到我已经创建了三个索引,并且还可以看到我的集群健康状态显示为yellow,上面说了yellow表示存在副本分片没有正常运行,因为我的elasticsearch集群只有一个节点,elasticsearch不能把同一索引的主分片和副本分配在一个节点上,这样也是没有意义的,因为只要一个节点挂了,节点上的主分片和副本上的数据就都丢失了,也就不存在什么高可用性了
创建文档
在命令行下执行下面的命令可以创建文档
curl -X PUT"192.168.179.134:9200/customer/_doc/1?pretty" -H 'Content-Type:application/json' -d'
{
"name": "John Doe"
}
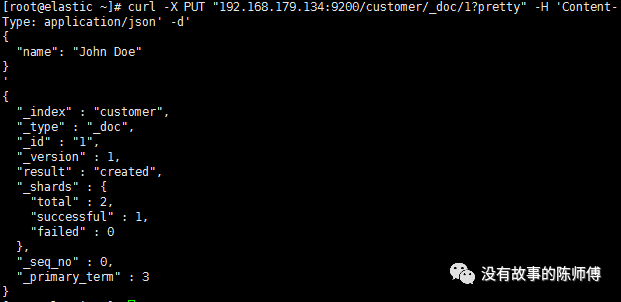
如图所示,我们刚刚在customer索引中创建了一个名为John Doe,ID为1的文档
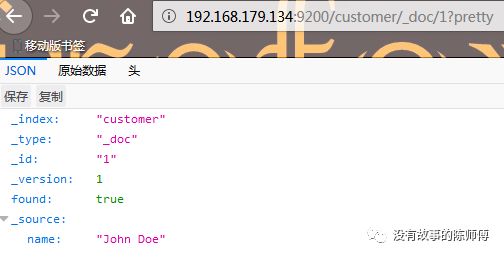
可以在浏览器使用http://192.168.179.134:9200/customer/_doc/1?pretty或者在命令行中输入curl -X GET192.168.179.134:9200/customer/_doc/1?pretty查看刚刚创建的文档
删除索引
在命令行中使用curl-X DELETE "192.168.179.134:9200/customer"命令可以删除索引
再次查看集群中的索引,会发现customer索引已经不见了

如果要删除全部索引的话可以执行curl -X DELETE "192.168.179.134:9200/_all"或者curl -X DELETE "192.168.179.134:9200/*"
其实可以发现,以上的几条命令都是有固定的命令格式
<REST动作>/<索引>/<类型>/<ID>
删除文档
在命令行执行命令curl-X DELETE "192.168.179.134:9200/customer/_doc/1?pretty"可以删除customer索引ID为1的文档
由于笔记还没有完成,先将部分笔记发公众号,等全部写完再丢github
参考链接:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
如果有想一起交流的朋友可以扫描下方二维码进入群聊