成功,通常指在某一适当的时候在某一适当的地方做了一件适当的事情。 ——戈登·摩尔,英特尔公司创始人之一
本文主要介绍了我在阅读《深入浅出DPDK》,《DPDK应用基础》这两本书中所划下的知识点
首先《深入浅出DPDK》这本书是intel的专家写的,而且《DPDK应用基础》的作者也有受到这本书的指导,这本书读完已经挺长时间了,记得当时花了两个周的时间来阅读此书,我自认为我的阅读速度比平常人要快一些,但即便如此,由于书中有太多的知识点,刚好又触及我的知识盲区,所以读完的时间久了点,不过有一说一,内容还是挺全面的,能从书中掌握其中的10%-20%我觉得就很厉害了,第一部分讲DPDK基础,第二部分介绍DPDK虚拟化,第三部分介绍DPDK的应用,理论知识偏多
《DPDK应用基础》虽然与《深入浅出DPDK》篇幅差不多,但阅读用的时间却是《深入浅出DPDK》的一半,这里没有踩一捧一的意思,只是做个对比,《深入浅出DPDK》的理论介绍要比《DPDK应用基础》多,不过这本书有很多地方都是从源码上介绍DPDK的原理,由于本人不是C开发,所以代码上有不明白的地方就快速翻过去了,书中还涉及到针对DPDK的测试方法,测试了不同变量之间的性能差异,这本书比较适合有c开发基础的dpdk工程师以及一些dpdk性能测试人员阅读。书中也是分了三个部分,第一部分讲dpdk的基础原理,第二部分介绍了DPDK的测试方法,第三部分还是介绍了dpdk应用开发的实例解析,其中包括vDPI、mTCP、BRAS的应用案例
接下来是个人认为是比较重要知识点的分享
《DPDK应用基础》笔记
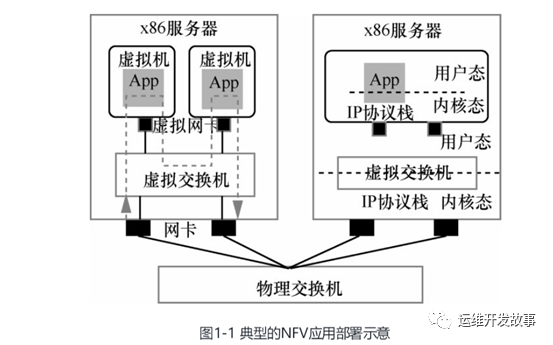
电信广域网业务要求网元(如 BNG、DPI等)具有高吞吐、低时延、海量流表支持和用户级QoS控制的特点。大量实践表明,通用x86服务器作为NFV基础设施用于高速转发业务时,面临着严重的转发性能瓶颈,需要针对性地从硬件架构、系统I/O、操作系统、虚拟化层、组网与流量调度和VNF功能等层面进行性能优化,才能达到各类NFV网络业务的高性能转发要求。
x86架构性能分析
在物理硬件中,处理器架构、CPU 核的数量、时钟速率、处理器内部缓冲尺寸、内存通道、内存时延、外设总线带宽和处理器间总线带宽以及CPU指令集等因素,对应用软件(VNF)有较大影响。多核处理器环境下的软件设计水平也会导致应用软件性能的差异。例如,基于流水线、多线程和防死锁的设计,对底层硬件架构的准确感知,根据CPU/核的负荷状态分配线程,执行内存就近访问等操作,均可极大提升通信进程的处理性能。操作系统作为应用软件与物理硬件间的桥梁,通过对物理资源进行合理抽象,不仅提供了多核实时运行环境、内存管理机制、独立内存访问(不同进程间)、文件系统等基本功能,还提供了诸如巨页表管理等高级功能。更大的页表可以减少从逻辑内存页面到物理内存的转换时间、增加缓存命中率,甚至为了获得更快的访问速度,这些地址转译映射可以保存在处理器的内部一个称为TLB(Translation Lookaside Buffer)的缓存中。但是,获得巨页表和TLB支持的前提,是需要对处理器和操作系统(Linux或者Windows)进行正确的配置。将不同的应用软件线程安排在特定处理器核上运行,这种调优方法可以大幅提升软件处理性能。由于I/O和内存访问的性能对整个NFV性能有决定性影响,因此目前的NFV性能优化技术往往都是旁路掉操作系统及其相关的I/O机制和中断机制。
虚拟化层的相关性能问题
在环境配置不当时,Hypervisor必然会引入一定的性能开销,例如成倍的内存页面转译、中断重映射、指令集转译等操作。随着Hypervisor技术的演进,这些开销目前已经大为减少,所采用的新技术包括以下几个方面。采用两级地址转译服务(硬件支持的虚拟化技术),CPU可以旁路Hypervisor而直接访问虚拟内存,并支持包括巨页表在内的地址转译,所以虚拟机内可以透明使用巨页表。针对I/O的IOMMU(Input Output Memory Management Unit,输入输出内存管理单元)或转译服务:针对I/O的两级内存地址提供转译服务和中断重映射、I/O巨页表转译,从而使I/O设备可以旁路Hypervisor而直接访问物理内存和I/O TLB处理器缓存。为处理器的一级缓存和TLB缓存新增部分新字段以避免缓存刷新,允许不同的虚拟机共享相同的缓存或TLB缓存而不会相互影响。I/O设备复用(如SR-IOV)技术则将单一PCIe设备分片为多个PCI设备,这些分片设备在PCI-SIG(Peripheral Component Interconnect Special Interest Group)中被称为虚拟化功能(Virtual Function,VF),拥有独立的配置空间、中断、I/O内存空间等。每个VF可以被直接分配给一个虚拟机使用,以避免Hypervisor带来的软件上下文切换。在虚拟机中,对报文收/发队列中的数据进行报文分类,允许一台虚拟机直接管理I/O中断,以避免Hypervisor中虚拟交换机的每个报文收发产生的单个中断。
NFV中的网络转发性能分析
-
网卡硬件中断目前大量流行的PCI/PCIe网卡在收到报文后,一般采用DMA方式直接写入内存并产生CPU硬件中断,当网络流量激增时,CPU大部分时间阻塞于中断响应。在多核系统中,可能存在多块网卡绑定同一个CPU核的情况,使其占用率达到100%。因此,网卡性能改进一般采用减少或关闭中断、多核CPU负载均衡等优化措施。 -
内核网络协议栈Linux或Free BSD系统中,用户态程序调用系统套接字进行数据收发时,会使用内核网络协议栈。这将产生两方面的性能问题:一是系统调用导致的内核上下文切换会频繁占用CPU周期;二是协议栈与用户进程间的报文复制是一种费时的操作。 NFV系统中,业务App报文从物理网卡到业务App需要完成收发操作各1次,至少经过多次上下文切换(宿主机2次以及VM内2次)和多次报文复制。将网络协议栈移植到用户态是一种可行思路,但这种方法可能违反GNU协议。因此,弃用网络协议栈以换取转发性能是唯一可行的办法,但需要付出大量修改业务App代码的代价。 -
虚拟化层的封装效率业务App中存在2类封装:服务器内部的I/O封装和网络层对数据报文的虚拟化封装。前者是由于NFV的业务App运行于VM中,流量需要经历多次封装/解封装过程:宿主机Hypervisor对VM的I/O封装(如QEMU)、虚拟交换机对端口的封装(如OVS的tap)、云管理平台对虚拟网络端口的封装;后者是为实现NFV用户隔离而在流量中添加的用户标识,如VLAN、Vx LAN等。这2类封装/解封均要消耗CPU周期,从而降低了NFV系统的转发效率。 -
业务链网络转发效率NFV的业务链存在星型和串行2种组网方式,星型连接依赖物理网络设备的硬件转发能力,整体转发性能较优,但当App(运行于x86服务器)的数量较大时,会消耗大量昂贵的网络设备端口。在业务链组网范围不大时,为简化组网和节约端口,可以考虑采用串行连接。在串行组网方式下,不合适的负载均衡算法会造成流量在不同进程组的上下行链路之间反复穿越,严重降低业务链网络的带宽利用率。
相关的优化思路如下。
-
优化网卡驱动采用应用层轮询或内核轮询机制,关闭网卡中断,释放CPU中断处理时间。 -
旁路内核协议栈,减少内核上下文切换数据通道应采用UIO技术,用户态进程直接读写网卡缓冲区,减少报文处理中的内核系统调用,但同时应保留协议栈功能供网络管理使用。 -
提供虚拟网络的性能优化虚拟交换机容易导致性能瓶颈,选择用户态虚拟交换机有利于提升性能和进行故障定位;方案应支持Open Flow功能,满足各类复杂的转发要求;可关闭不必要的虚拟化端口和封装,减少CPU开销。 -
提供VM内部I/O优化能力优化方案应能覆盖对VM内部的虚拟网卡及其业务App转发通道的性能提升。 -
与OpenStack类云管理平台的无缝对接优化技术不能影响OpenStack相关网络插件和虚拟网络的管理。 -
支持CPU与网络资源的负载分担利用CPU亲和性技术,可按需调整和定制多核CPU的负载分布
DPDK组成结构
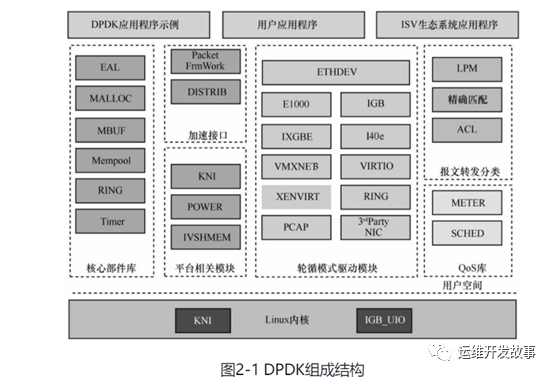
轮询模式驱动模块PMD相关API实现了在轮询方式下进行网卡报文收发,避免了常规报文处理方法中因采用中断方式造成的响应时延,极大提升了网卡收发性能。
巨页技术
Linux操作系统中,整个物理内存按帧(Frame)进行管理,虚拟内存按照页(Page)进行管理。内存管理单元(MMU)完成从虚拟内存地址到物理内存地址的转换。内存管理单元进行地址转换需要的信息保存在一个叫页表(PageTable)的数据结构里面,页表查找是一种极其耗时的操作。为了减少页表的查找过程,Intel 处理器实现了以一块缓存来保存查找结果,这块缓存被称为 TLB (Translation Lookaside Buffer),它保存了虚拟地址到物理地址的映射关系。所有虚拟地址在转换为物理地址以前,处理器会首先在TLB中查找是否已经存在有效的映射关系,如果没有发现有效的映射,也就是TLS miss,处理器再进行页表的查找。页表的查找过程对性能影响极大,因此需要尽量减少TLB miss的发生。
DPDK则利用巨页技术,所有的内存都是从巨页里分配,实现对内存池(Mempool)的管理,并预先分配好同样大小的mbuf,供每一个数据分组使用。Linux巨页机制利用了处理器核上的的TLB的巨页表项,这可以减少内存地址转换的开销。
轮询技术
轮询技术传统网卡的报文接收/发送过程中,网卡硬件收到网络报文,或发送完网络报文后,需要发送中断到CPU,通知应用软件有网络报文需要处理。在x86处理器上,一次中断处理需要将处理器的状态寄存器保存到堆栈,并运行中断服务程序,最后再将保存的状态寄存器信息从堆栈中恢复。整个过程需要至少300个处理器时钟周期。对于高性能网络处理应用,频繁的中断处理开销极大地降低了网络应用程序的性能。
为了减少中断处理开销,DPDK使用了轮询技术来处理网络报文。网卡收到报文后,直接将报文保存到处理器缓存中(有DDIO(Direct Data I/O)技术的情况下),或者内存中(没有DDIO技术的情况下),并设置报文到达的标志位。应用软件则周期性地轮询报文到达的标志位,检测是否有新报文需要处理。整个过程中完全没有中断处理过程。
CPU亲和技术
多个进程或线程在多核处理器的某一个核上不断地交替执行。每次切换过程,都需要将处理器的状态寄存器保存在堆栈中,并恢复当前进程的状态信息,这对系统是一种处理开销。将一个线程固定在一个核上运行,可以消除切换带来的额外开销。另外,将进程或者线程迁移到多核处理器的其他核上运行时,处理器缓存中的数据也需要进行清除,导致处理器缓存的利用效果降低。CPU 亲和技术,就是将某个进程或者线程绑定到特定的一个或者多个核上执行,而不被迁移到其他核上,这样就保证了专用程序的性能。
DPDK使用了Linux pthread库,在系统中把相应的线程和CPU进行亲和性绑定, 然后相应的线程尽可能使用独立的资源进行相关的数据处理。
硬件结构对DPDK性能的影响
硬件规格对DPDK性能的影响体现在几个方面。
-
CPU频率:CPU频率越高,DPDK性能越高。 -
LLC(Last Leve Cache,最后检测缓存)大小:缓存越大,DPDK性能越高。 -
PCIe(数据通路)的数目:PCIe链路可以支持1、2、4、8、12、16和32个,即×1、×2、×4、×8、×12、×16和×32宽度的PCIe链路,需要确保其带宽可以满足所插网卡的带宽。 -
NUMA:网络数据报文的处理由网卡所在的NUMA(Non Uniform Memory Access,非统一内存访问)节点处理,将会比远端NUMA节点处理的性能更高。
OS调整示例
绝大部分的操作需要同时在Host操作系统和Guest操作系统上应用。
-
对DPDK应用使用处理器核进行隔离。修改Linux的OS的GRUB参数,示例如下。
设置isol CPUs=16-23,40-47
-
打开运行有DPDK进程的处理器核上的nohz_full。nohz_full可以减少内核的周期性时钟中断的次数。修改Linux的OS的GRUB参数,示例如下。
设置nohz_full=16-23,40-47
-
关闭NMI监控功能,减少NMI中断对DPDK任务的干扰。修改Linux的OS的GRUB参数,示例如下。
设置nmi_watchdog=0
-
关闭SELinux功能。修改Linux的OS的GRUB参数,示例如下。
设置selinux=0
-
关闭处理器的P状态调整和softlockup功能。将处理器锁定在固定的频率运行,减少处理器在不同的P状态切换带来的处理时延。修改Linux的OS的GRUB参数,示例如下。
设置intel_pstate=disable nosoftlockup
-
关闭KVM的内存页合并服务。调用命令如下。
systemctl disable ksm.service
systemctl disable ksmtuned.service
DPDK在NFV中的应用场景
在X86服务器上的应用
VNF软件的形式直接运行在x86服务器OS上,同时在物理服务器上加载DPDK组件。此时,DPDK接管了物理网卡的I/O驱动, VNF也不再使用传统Linux内核网络协议栈,而是通过调用DPDK的用户态API进行快速转发。同时,DPDK进程使用少量的处理器核(如 2 个核)与内存以满足高速转发处理, VNF使用剩余的全部硬件资源用于转发,本方案适用于DPI和FW等资源利用率长期较高的网络业务。
虚拟机+OVS的应用
满足VNF之间可能发生的东西向流量交换或者共享物理网卡的需求,可以在x86服务器 OS上安装OVS虚拟交换机,用于连接各个VNF和x86服务器的物理网卡端口。本场景下,多个 VNF 一般属于不同类型的应用程序,VNF 之间可能产生交互流量。
因主要的性能瓶颈存在于VNF的虚拟I/O通道和OVS交换机,DPDK需要分别安装在运行VNF的VM镜像内部和运行OVS的物理服务器OS上。前者用于优化VM内部的VNF数据平面转发性能,包括提供虚拟化网卡驱动、提供用户态转发API等, DPDK的各种配置方法与VNF运行在x86服务器中的机制类似,VNF并不能感知是运行在VM环境;后者用于优化OVS交换机性能,连接VM与各NUMA节点上的DPDK端口。该方案可以实现VNF的灵活扩容/缩容以及在资源池中按需迁移,方案中的第三方VNF厂商可以屏蔽物理设备差异,提供各自的高性能业务产品。同时,使用经过DPDK优化后的OVS交换机,可以实现VNF间流量的灵活转发与互联互通,节省硬件交换机。
虚拟机+SR-IOV技术的应用
SR-IOV技术使得各VM的虚拟网卡可以直接连至x86服务器的物理网卡进行数据收发,如同独占物理网卡一样。该方案适用于VNF间无需东西向流量交互的场景,或者基于硬件交换机进行VNF互连的场景。由于旁路了服务器的虚拟化层实现直接转发,可以达到近似物理转发的性能。
《深入浅出DPDK》笔记
亲和性与独占
DPDK工作在用户态,线程的调度仍然依赖内核。利用线程的CPU亲和绑定的方式,特定任务可以被指定只在某个核上工作。好处是可避免线程在不同核间频繁切换,核间线程切换容易导致因cache miss和cache write back造成的大量性能损失。如果更进一步地限定某些核不参与Linux系统调度,就可能使线程独占该核,保证更多cache hit的同时,也避免了同一个核内的多任务切换开销
其实包转发的天花板就是理论物理线路上能够传送的最大速率,即线速。那数据包经过网络接口进入内存,会经过I/O总线(例如,PCIe bus), I/O总线也有天花板,实际事务传输不可能超过总线最大带宽。 计算机系统中一般都有两个标准化的部分:北桥(North Bridge)和南桥(SouthBridge)。它们是处理器和内存以及其他外设沟通的渠道。处理器和内存系统通过前端总线(FrontSide Bus, FSB)相连,当处理器需要读取或者写回数据时,就通过前端总线和内存控制器通信。
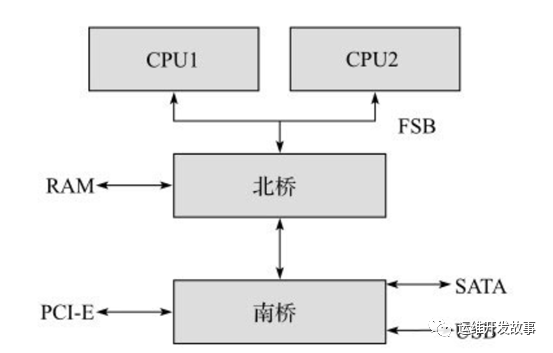
该架构所有的处理器共用一条前端总线与北桥相连。北桥也称为主桥(HostBridge),主要用来处理高速信号,通常负责与处理器的联系,并控制内存AGP、PCI数据在北桥内部传输。而北桥中往往集成了一个内存控制器(最近几年英特尔的处理器已经把内存控制器集成到了处理器内部),根据不同的内存,比如SRAM、DRAM、SDRAM,集成的内存控制器也不一样。南桥也称为IO桥(IO bridge),负责I/O总线之间的通信,比如PCI总线、SATA、USB等,可以连接光驱、硬盘、键盘灯设备交换数据。在这种系统中,所有的数据交换都需要通过北桥:
-
处理器访问内存需要通过北桥。 -
处理器访问所有的外设都需要通过北桥。 -
处理器之间的数据交换也需要通过北桥。 -
挂在南桥的所有设备访问内存也需要通过北桥。为了解决这个瓶颈,产生了NUMA(Non-Uniform Memory Architecture,非一致性内存架构)系统。
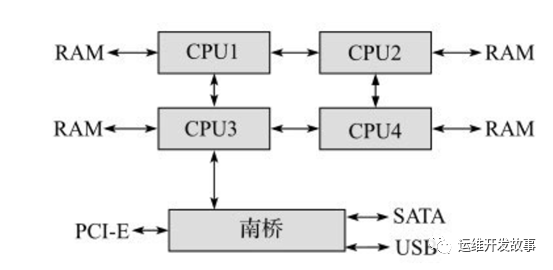
该系统中,访问内存所花的时间和处理器相关。之所以和处理器相关是因为该系统每个处理器都有本地内存(Local memory),访问本地内存的时间很短,而访问远程内存(remote memory),即其他处理器的本地内存,需要通过额外的总线!对于某个处理器来说,当其要访问其他的内存时,轻者要经过另外一个处理器,重者要经过2个处理器,才能达到访问非本地内存的目的,因此内存与处理器的“距离”不同
超线程(Hyper-Threading)
在一个处理器中提供两个逻辑执行线程,逻辑线程共享流水线、执行单元和缓存。该技术的本质是复用单处理器中的超标量流水线的多路执行单元,降低多路执行单元中因指令依赖造成的执行单元闲置。对于每个逻辑线程,拥有完整独立的寄存器集合和本地中断逻辑,从软件的角度,与单线程物理核并没有差异。采用超线程,在单核上可以同时进行多线程处理,使整体性能得到一定程度提升。DPDK是一种I/O集中的负载,对于这类负载,IPC相对不是特别高,所以超线程技术会有一定程度的帮助。
异步中断模式
当有包进入网卡收包队列后,网卡会产生硬件(MSIX/MSI/INTX)中断,进而触发CPU中断,进入中断服务程序,在中断服务程序(包含下半部)来完成收包的处理。当然为了改善包处理性能,也可以在中断处理过程中加入轮询,来避免过多的中断响应次数。总体而言,基于异步中断信号模式的收包,是不断地在做中断处理,上下文切换,每次处理这种开销是固定的,累加带来的负荷显而易见。在CPU比I/O速率高很多时,这个负荷可以被相对忽略,问题不大,但如果连接的是高速网卡且I/O频繁,大量数据进出系统,开销累加就被充分放大。中断是异步方式,因此CPU无需阻塞等待,有效利用率较高,特别是在收包吞吐率比较低或者没有包进入收包队列的时候,CPU可以用于其他任务处理。
当有包需要发送出去的时候,基于异步中断信号的驱动程序会准备好要发送的包,配置好发送队列的各个描述符。在包被真正发送完成时,网卡同样会产生硬件中断信号,进而触发CPU中断,进入中断服务程序,来完成发包后的处理,例如释放缓存等。与收包一样,发送过程也会包含不断地做中断处理,上下文切换,每次中断都带来CPU开销;同上,CPU有效利用率高,特别是在发包吞吐率比较低或者完全没有发包的情况。
轮询模式
DPDK起初的纯轮询模式是指收发包完全不使用任何中断,集中所有运算资源用于报文处理。但这不是意味着DPDK不可以支持任何中断。根据应用场景需要,中断可以被支持,最典型的就是链路层状态发生变化的中断触发与处理。DPDK纯轮询模式是指收发包完全不使用中断处理的高吞吐率的方式。DPDK所有的收发包有关的中断在物理端口初始化的时候都会关闭,也就是说,CPU这边在任何时候都不会收到收包或者发包成功的中断信号,也不需要任何收发包有关的中断处理。
DPDK的轮询驱动程序负责初始化好每一个收包描述符,其中就包含把包缓冲内存块的物理地址填充到收包描述符对应的位置,以及把对应的收包成功标志复位。然后驱动程序修改相应的队列管理寄存器来通知网卡硬件队列里面的哪些位置的描述符是可以有硬件把收到的包填充进来的。网卡硬件会把收到的包一一填充到对应的收包描述符表示的缓冲内存块里面,同时把必要的信息填充到收包描述符里面,其中最重要的就是标记好收包成功标志。当一个收包描述符所代表的缓冲内存块大小不够存放一个完整的包时,这时候就可能需要两个甚至多个收包描述符来处理一个包。
每一个收包队列,DPDK都会有一个对应的软件线程负责轮询里面的收包描述符的收包成功的标志。一旦发现某一个收包描述符的收包成功标志被硬件置位了,就意味着有一个包已经进入到网卡,并且网卡已经存储到描述符对应的缓冲内存块里面,这时候驱动程序会解析相应的收包描述符,提取各种有用的信息,然后填充对应的缓冲内存块头部。然后把收包缓冲内存块存放到收包函数提供的数组里面,同时分配好一个新的缓冲内存块给这个描述符,以便下一次收包。
每一个发包队列,DPDK都会有一个对应的软件线程负责设置需要发送出去的包,DPDK的驱动程序负责提取发包缓冲内存块的有效信息,例如包长、地址、校验和信息、VLAN配置信息等。DPDK的轮询驱动程序根据内存缓存块中的包的内容来负责初始化好每一个发包描述符,驱动程序会把每个包翻译成为一个或者多个发包描述符里能够理解的内容,然后写入发包描述符。
混合中断轮询模式
由于实际网络应用中可能存在的潮汐效应,在某些时间段网络数据流量可能很低,甚至完全没有需要处理的包,这样就会出现在高速端口下低负荷运行的场景,而完全轮询的方式会让处理器一直全速运行,明显浪费处理能力和不节能。因此在DPDK R2.1和R2.2陆续添加了收包中断与轮询的混合模式的支持,类似NAPI的思路,用户可以根据实际应用场景来选择完全轮询模式,或者混合中断轮询模式。而且,完全由用户来制定中断和轮询的切换策略。
应用程序开始就是轮询收包,这时候收包中断是关闭的。但是当连续多次收到的包的个数为零的时候,应用程序定义了一个简单的策略来决定是否以及什么时候让对应的收包线程进入休眠模式,并且在休眠之前使能收包中断。休眠之后对应的核的运算能力就被释放出来,完全可以用于其他任何运算,或者干脆进入省电模式,取决于内核怎么调度。当后续有任何包收到的时候,会产生一个收包中断,并且最终唤醒对应的应用程序收包线程。线程被唤醒后,就会关闭收包中断,再次轮询收包。当然,应用程序完全可以根据不同的需要来定义不同的策略来让收包线程休眠或者唤醒收包线程。DPDK的混合中断轮询机制是基于UIO或VFIO来实现其收包中断通知与处理流程的。如果是基于VFIO的实现,该中断机制是可以支持队列级别的,即一个接收队列对应一个中断号,这是因为VFIO支持多MSI-X中断号。但如果是基于UIO的实现,该中断机制就只支持一个中断号,所有的队列共享一个中断号。
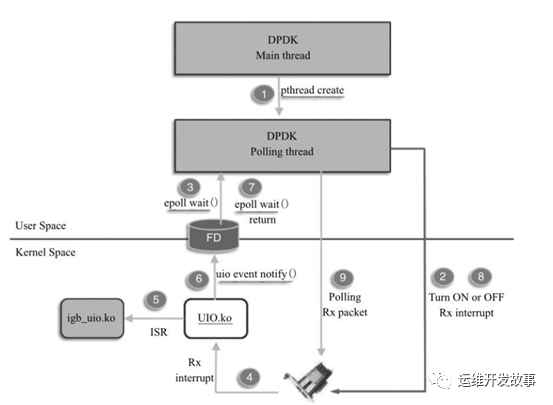
当然混合中断轮询模式相比完全轮询模式,会在包处理性能和时延方面有一定的牺牲,比如由于需要把DPDK工作线程从睡眠状态唤醒并运行,这样会引起中断触发后的第一个接收报文的时延增加。由于时延的增加,需要适当调整Mbuf队列的大小,以避免当大量报文同时到达时可能发生的丢包现象。
硬件平台对包处理性能的影响
在多处理器平台上,不同的PCIe插槽可能连接在不同的处理器上,跨处理器的PCIe设备访问会引入额外的CPU间通信,对性能的影响大。PCIe插槽与具体哪路CPU连接,在主板设计上基本确定,如果看不到物理插卡的具体位置(较少场合),一个简单的软件方法是查看PCIe地址中总线编号,如果小于80(例如0000:03:00.0),是连接到CPU0上,大于等于80(比如0000:81:00.0),则是连接在CPU1上。软件识别方法并不可靠,且会随着操作系统与驱动程序变化。
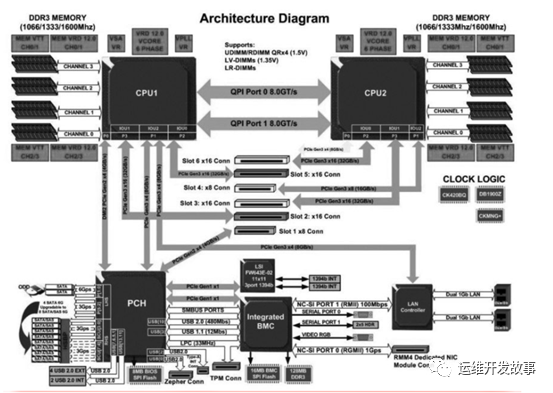
软件平台对包处理性能的影响
操作系统一般需要选用比较新的内核版本,并且是广泛使用和没有发现严重问题的操作系统。DPDK广泛使用了大页(2M或者1G)机制,以Linux系统为例,1G的大页一般不能在系统加载后动态分配,所以一般会在内核加载的时候设置好需要用到的大页。例如,增加内核启动参数“default_hugepagesz=1G hugepagesz=1G hugepages=8”来配置好8个1G的大页。在Linux系统上,可以通过命令“cat /proc/meminfo”来查看系统加载后的内存状况和大页的分配状况。
DPDK的软件线程一般都需要独占一些处理器的物理核或者逻辑核来完成稳定和高性能的包处理,如果硬件平台的处理器有足够多的核,一般都会预留出一些核来给DPDK应用程序使用。例如,增加内核启动参数“isolcpus=2, 3, 4, 5, 6, 7, 8”,使处理器上ID为2,3,4,5, 6,7,8的逻辑核不被操作系统调度。
在双路处理器系统上遵循就近原则,DPDK一般要求尽量避免使用跨处理器的核来处理网卡设备上的收发包,所以需要了解核ID和处理器的对应关系,以及网卡端口和处理器的连接关系。在Linux系统上,可以通过命令“lscpu”来查看核ID和处理器的对应关系。
I/O虚拟化
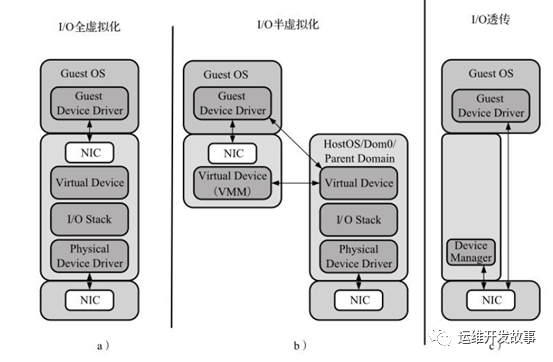
I/O虚拟化包括管理虚拟设备和共享的物理硬件之间I/O请求的路由选择。目前,实现I/O虚拟化有三种方式:I/O全虚拟化、I/O半虚拟化和I/O透传。
I/O全虚拟化
该方法可以模拟一些真实设备。一个设备的所有功能或总线结构(如设备枚举、识别、中断和DMA)都可以在宿主机中模拟。客户机所能看到的就是一组统一的I/O设备。宿主机截获客户机对I/O设备的访问请求,然后通过软件模拟真实的硬件。这种方式对客户机而言非常透明,无需考虑底层硬件的情况,不需要修改操作系统。宿主机必须从设备硬件的最底层开始模拟,尽管这样可以模拟得很彻底,以至于客户机操作系统完全不会感知到是运行在一个模拟环境中,但它的效率比较低。
I/O半虚拟化
半虚拟化的意思就是说客户机操作系统能够感知到自己是虚拟机。对于I/O系统来说,通过前端驱动/后端驱动模拟实现I/O虚拟化。客户机中的驱动程序为前端,宿主机提供的与客户机通信的驱动程序为后端。前端驱动将客户机的请求通过与宿主机间的特殊通信机制发送给后端驱动,后端驱动在处理完请求后再发送给物理驱动。不同的宿主机使用不同的技术来实现半虚拟化。比如说XEN,就是通过事件通道、授权表以及共享内存的机制来使得虚拟机中的前端驱动和宿主机中的后端驱动来通信。
在全虚拟化中是所有对模拟I/O设备的访问都会造成VM-Exit,而在半虚拟化中是通过前后端驱动的协商,使数据传输中对共享内存的读写操作不会VM-Exit,这种方式由于不像模拟器那么复杂,软件处理起来不至于那么慢,可以有更高的带宽和更好的性能。但是,这种方式与I/O透传相比还是存在性能问题,仍然达不到物理硬件的速度。
I/O透传
直接把物理设备分配给虚拟机使用,例如直接分配一个硬盘或网卡给虚拟机,如图10-4c所示。这种方式需要硬件平台具备I/O透传技术,例如Intel VT-d技术。它能获得近乎本地的性能,并且CPU开销不高。DPDK支持半虚拟化的前端virtio和后端vhost,并且对前后端都有性能加速的设计,这些将分别在后面两章介绍。而对于I/O透传,DPDK可以直接在客户机里使用,就像在宿主机里,直接接管物理设备,进行操作。I/O透传带来的好处是高性能,几乎可以获得本机的性能,这个主要是因为Intel®VT-d的技术支持,在执行IO操作时大量减少甚至避免VM-Exit陷入到宿主机中。目前只有PCI和PCI-e设备支持Intel®VT-d技术。 它的不足有以下两点:
-
x86平台上的PCI和PCI-e设备是有限的,大量使用VT-d独立分配设备给客户机,会增加硬件成本。
-
PCI/PCI-e透传的设备,其动态迁移功能受限。动态迁移是指将一个客户机的运行状态完整保存下来,从一台物理服务器迁移到另一台服务器上,很快地恢复运行,用户不会察觉到任何差异。原因在于宿主机无法感知该透传设备的内部状态,因此也无法在另一台服务器恢复其状态。 针对这些不足的可能解决办法有以下几种:
-
在物理主机上,仅少数对IO性能要求高的客户机使用VT-d直接分配设备,其他的客户机可以使用纯模拟或者virtio以达到多个客户机共享一个设备的目的。
-
在客户机里,分配两个设备,一个是PCI/PCI-e透传设备,一个是模拟设备。DPDK通过bonding技术把这两个设备设成主备模式。当需要动态迁移时,通过DPDK PCI/PCI-e热插拔技术把透传设备从系统中拔出,切换到模拟设备工作,动态迁移结束后,再通过PCI/PCI-e热插拔技术把透传设备插入系统中,切换到透传设备工作。至此,整个过程结束。
-
可以选择SR-IOV,让一个网卡生成多个独立的虚拟网卡,把这些虚拟网卡分配给每一个客户机,可以获得相对好的性能,但是这种方案也受限于PCI/PCIe带宽或者是SR-IOV扩展性的性能。
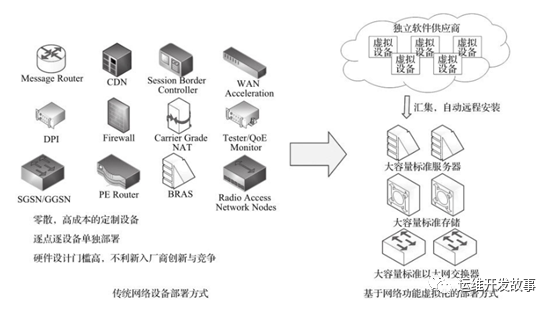
DPDK与网络功能虚拟化
传统的电信运营商的网络极其复杂,设备类型繁多。而网络功能虚拟化旨在改变网络架构师的工作方式,通过标准的虚拟化技术将许多网络设备迁移到符合工业标准的大容量服务器、交换机和存储上。在一个标准服务器上,软件定义的网络功能可以随意在不同的网络位置之间创建、迁移、删除,无需改变设备的物理部署。
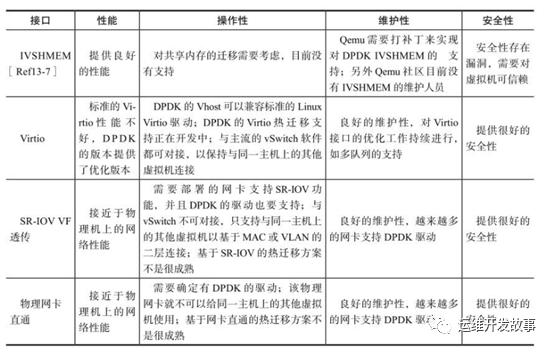
目前NFVI提供给虚拟机的网络接口主要有四种方式:IVSHMEM共享内存的PCI设备,半虚拟化virtio设备,SR-IOV的VF透传,以及物理网卡透传
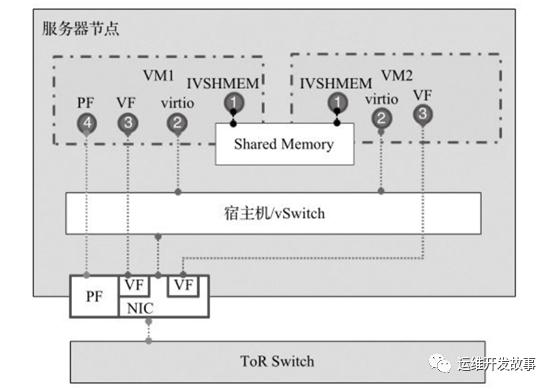
下面从性能、操作性、迁移性和安全性来简要比较Virtio以及SR-IOV VF/PF直通接口的优缺点,给VNF的实现在网络接口的选择提供一些建议。