富在术数,不在劳身;利在势居,不在力耕 《盐铁论》
Redis简介
Redis 是一个开源的使用 ANSI C 语言编写、遵守 BSD 协议、支持网络、可基于内存亦可持久化的日志型、Key-Value 数据库,并提供多种语言的 API。
它通常被称为数据结构服务器,因为值(value)可以是 字符串(String), 哈希(Map),列表(list),集合(sets)和 有序集合(sorted sets)等类型。
Redis安装
$ wget http://download.redis.io/releases/redis-5.0.5.tar.gz
$ tar xzf redis-5.0.5.tar.gz
$ cd redis-5.0.5
$ make以后台方式启动Redis
修改Redis.conf文件
将daemonize on
修改为
daemonize yes启动Redis
src/redis-server redis.conf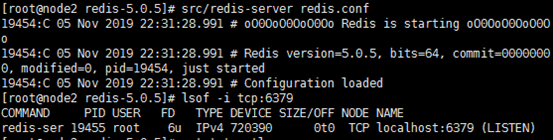
开机启动Redis
执行安装脚本,一直默认就可以
./utils/install_server.sh
mv /etc/init.d/redis_6379 /etc/init.d/redis设置Redis密码
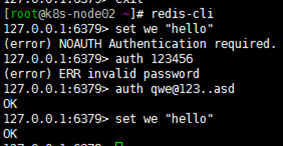
vim /etc/redis/6379.conf
requirepass redispass
service redis restart再次连接发现需要输入密码
Redis命令
全局命令
获取键
keys patternkeys还支持通配符
127.0.0.1:6379> set we "hello"
OK
127.0.0.1:6379> keys *
1) "we"
127.0.0.1:6379> set name wanger
OK
127.0.0.1:6379> keys name
1) "name"
127.0.0.1:6379> keys *
1) "name"
2) "we"keys 命令遍历了Redis中所有的键,当键的数量过多时会影响Redis性能
删除键
del key1 key2 ..例如:
127.0.0.1:6379> keys *
1) "qwe"
2) "asd"
3) "we"
127.0.0.1:6379> del asd qwe
(integer) 2
127.0.0.1:6379> keys *
1) "we"判断键是否存在
exists key1 key2例如:
127.0.0.1:6379> exists we
(integer) 1
127.0.0.1:6379> exists name
(integer) 0
127.0.0.1:6379> set qwe 2
OK
127.0.0.1:6379> exists we qwe
(integer) 2
127.0.0.1:6379> exists we name
(integer) 1获取键的总数
dbsize例如:
127.0.0.1:6379> dbsize
(integer) 2
127.0.0.1:6379> keys *
1) "qwe"
2) "we"获取键的数据类型
type key例如:
127.0.0.1:6379> type we
string
127.0.0.1:6379> lpush list1 1 2 3
(integer) 3
127.0.0.1:6379> type list1
list对列表、集合、有序集合的元素进行排序
sort key [BY pattern] [LIMIT offset count] [GET pattern [GET pattern ...]] [ASC|DESC] [ALPHA] [STORE destination]例如:
127.0.0.1:6379> lrange list 0 -1
1) "5"
2) "7"
3) "2"
4) "4"
5) "3"
6) "1"
sort list desc limit 0 5
1) "7"
2) "5"
3) "4"
4) "4"
5) "3"
127.0.0.1:6379> lpush list2 asd qwe zxc
(integer) 3
sort list2 desc limit 0 5 alpha
1) "zxc"
2) "qwe"
3) "asd"清空数据库
flushdb //清空当前数据库
flushall //清空所有数据库例如:
127.0.0.1:6379[11]> set a 1
OK
127.0.0.1:6379[11]> get a
"1"
127.0.0.1:6379[11]> flushdb
OK
127.0.0.1:6379[11]> get a
(nil)将指定的键移动到其他数据库
move key db例如:
127.0.0.1:6379[11]> set a 1
OK
127.0.0.1:6379[11]> move a 2
(integer) 1
127.0.0.1:6379[11]> select 2
OK
127.0.0.1:6379[2]> get a
"1"字符串
字符串类型是Redis最基础的数据结构,字符串类型是其他几种数据类型的基础,他能存储任何形式的字符串,包括二进制数据
设值取值
set key value [EX seconds] [PX milliseconds] [NX|XX]
get key-
nx:
键必须不存在,才可以设置成功,用于添加。
-
xx:
与nx相反,键必须存在,才可以设置成功,用于更新
例如:
127.0.0.1:6379> set name wanger
OK
127.0.0.1:6379> get name
"wanger"
127.0.0.1:6379> setnx name wanger
(integer) 0
127.0.0.1:6379> set name wang xx
OK批量设值取值
mset key1 value1 key2 value2 ..
mget key1 key2例如:
127.0.0.1:6379> mset key1 1 key2 2
OK
127.0.0.1:6379> mget key1 key2
1) "1"
2) "2"对键值自增自减
incr key
decr key例如:
127.0.0.1:6379> incr key1
(integer) 2
127.0.0.1:6379> incr key2
(integer) 3
127.0.0.1:6379> get key1
"2"
127.0.0.1:6379> get key2
"3"
127.0.0.1:6379> get we
"hello"
127.0.0.1:6379> incr we
(error) ERR value is not an integer or out of range
127.0.0.1:6379> decr key1
(integer) 1
127.0.0.1:6379> decr key2
(integer) 2追加值
append key value例如:
127.0.0.1:6379> append key hello
(integer) 5
127.0.0.1:6379> append key world
(integer) 10
127.0.0.1:6379> get key
"helloworld"获取字符串长度
strlen key例如:
127.0.0.1:6379> get key
"helloworld"
127.0.0.1:6379> strlen key
(integer) 10
127.0.0.1:6379> set name "王二"
OK
127.0.0.1:6379> strlen name
(integer) 6设置和获取指定位置的字符串
setrange key offset value
getrange key start end例如:
127.0.0.1:6379> SET key1 "Hello World"
OK
127.0.0.1:6379> setrange key1 6 "Redis"
(integer) 11
127.0.0.1:6379> get key1
"Hello Redis"
127.0.0.1:6379> getrange key1 6 12
"Redis"字符串对象编码
字符串类型的内部编码有3种:
-
int:
8个字节的长整型。
-
embstr:
小于等于39个字节的字符串。
-
raw:
大于39个字节的字符串。
例如:
127.0.0.1:6379> set num 123456
OK
127.0.0.1:6379> object encoding num
"int"
127.0.0.1:6379> set short qweasd
OK
127.0.0.1:6379> object encoding short
"embstr"
127.0.0.1:6379> set raw "when you love me I have lost of plot wow wow"
OK
127.0.0.1:6379> object encoding raw
"raw"列表
Redis列表可以存储一个有序的字符串列表,内部使用双向链表实现,双向链表作为一种常见的数据结构,双向链表的每个数据节点都有两个指针,分别指向后继与前驱节点,从双向链表中的任意一个节点开始都可以很方便地访问其前驱与后继节点,因此获取越接近两端的元素就越快
从左右两边插入元素或者从某一个元素前后插入数据
lpush key value1 value2 value3
rpush key value1 value2 value3
linsert key BEFORE|AFTER pivot value例如:
127.0.0.1:6379> lpush names 1 2 3 4
(integer) 4
127.0.0.1:6379> lrange names 0 4
1) "4"
2) "3"
3) "2"
4) "1"
127.0.0.1:6379> rpush nums 1 2 3 4
(integer) 4
127.0.0.1:6379> lrange nums 0 4
1) "1"
2) "2"
3) "3"
4) "4"
127.0.0.1:6379> linsert nums before 2 5
(integer) 5
127.0.0.1:6379> lrange nums 0 5
1) "1"
2) "5"
3) "2"
4) "3"
5) "4"从列表两端删除元素
lpop key
rpop key例如:
127.0.0.1:6379> lrange nums 0 5
1) "1"
2) "5"
3) "2"
4) "3"
5) "4"
127.0.0.1:6379> lpop nums
"1"
127.0.0.1:6379> rpop nums
"4"
127.0.0.1:6379> lrange nums 0 5
1) "5"
2) "2"
3) "3"获取给定位置上的元素
lindex key index例如:
127.0.0.1:6379> lrange nums 0 5
1) "5"
2) "2"
3) "3"
127.0.0.1:6379> lindex nums 2
"3"
127.0.0.1:6379> lindex nums 1
"2"
127.0.0.1:6379> lindex nums -1
"3"获取给定范围的元素
lrange key start stop例如:
127.0.0.1:6379> lrange nums 0 1
1) "5"
2) "2"
127.0.0.1:6379> lrange nums 0 2
1) "5"
2) "2"
3) "3"获取列表长度
llen key例如:
127.0.0.1:6379> lrange nums 0 3
1) "5"
2) "2"
3) "3"
127.0.0.1:6379> llen nums
(integer) 3从列表中删除值
lrem key count value-
count > 0:
删除数量为count的从头到尾移动的值为value的元素。
-
count < 0:
删除数量为count的从尾到头移动的值为value的元素。
-
count = 0:
删除所有等于value的元素。
例如:
127.0.0.1:6379> lrange mylist 0 10
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "2"
7) "3"
8) "4"
9) "5"
10) "5"
127.0.0.1:6379> lrem mylist 1 5
(integer) 1
127.0.0.1:6379> lrange mylist 0 10
1) "1"
2) "2"
3) "3"
4) "4"
5) "2"
6) "3"
7) "4"
8) "5"
9) "5"
127.0.0.1:6379> lrem mylist -2 5
(integer) 2
127.0.0.1:6379> lrange mylist 0 10
1) "1"
2) "2"
3) "3"
4) "4"
5) "2"
6) "3"
7) "4"
127.0.0.1:6379> lrem mylist 0 2
(integer) 2
127.0.0.1:6379> lrange mylist 0 11
1) "1"
2) "3"
3) "4"
4) "3"
5) "4"修改指定索引的元素
lset key index value例如:
127.0.0.1:6379> lrange mylist 0 6
1) "1"
2) "3"
3) "4"
4) "3"
5) "4"
127.0.0.1:6379> lset mylist 1 5
OK
127.0.0.1:6379> lrange mylist 0 6
1) "1"
2) "5"
3) "4"
4) "3"
5) "4"阻塞操作
blpop和brpop分别是lpop和rpop的阻塞版本,功能类似,当列表为空时,会发生阻塞,timeout可定义阻塞时间,timeout为0时将一直阻塞,直到在另一个客户端中往列表中加入元素
blpop key1 key2 timeout
brpop key1 key2 timeout例如:
127.0.0.1:6379> lrange list2 0 4
1) "4"
2) "3"
3) "2"
127.0.0.1:6379> lrange list1 0 4
1) "8"
2) "7"
127.0.0.1:6379> blpop list1 list2 0
1) "list1"
2) "8"
127.0.0.1:6379> brpop list1 list2 0
1) "list1"
2) "7"
127.0.0.1:6379> brpop list1 list2 0
1) "list2"
2) "2"
127.0.0.1:6379> brpop list1 list2 0
1) "list2"
2) "3"
127.0.0.1:6379> brpop list1 list2 0
1) "list2"
2) "4"
127.0.0.1:6379> brpop list1 list2 0
1) "list2"
2) "1"
(18.49s)
在另一个客户端执行
127.0.0.1:6379> lpush list2 1
(integer) 1列表内部编码
-
ziplist(压缩列表):
列表元素保存的所有字符串元素的长度都小于64字节且元素数量小于512个时使用ziplist编码
-
linkedlist(链表):
当列表类型无法满足两个条件的任意一个的时候,redis会使用linkedlist作为列表的内部实现
-
quicklist:
list的内部实现quicklist是一个ziplist的双向链表,双向链表是由多个节点(Node)组成的,quicklist的每个节点都是一个ziplist。
参考张铁蕾http://zhangtielei.com/posts/blog-redis-quicklist.html
哈希
哈希是由与值关联的字段组成的映射。字段和值都是字符串,哈希类型中的映射关系叫作field-value
设值取值
hset key field value
hget key field例如:
127.0.0.1:6379> hset ha name wanger
(integer) 1
127.0.0.1:6379> hget ha name
"wanger"批量设值取值
hmset key field1 value1 field2 value2
hmget key field1 field2例如:
127.0.0.1:6379> hmset he name wanger sex nan
OK
127.0.0.1:6379> hmget he name sex
1) "wanger"
2) "nan"删除field
hdel key field1 field2例如:
127.0.0.1:6379> hdel he name
(integer) 1
127.0.0.1:6379> hget he name
(nil)获取field个数
hlen key例如:
127.0.0.1:6379> hmset he name wanger sex nan age 18
OK
127.0.0.1:6379> hlen he
(integer) 3获取哈希中的所有字段和值
hgetall key例如:
127.0.0.1:6379> hgetall he
1) "sex"
2) "nan"
3) "name"
4) "wanger"
5) "age"
6) "18"获取哈希中的所有字段
hkeys key例如:
127.0.0.1:6379> hkeys he
1) "sex"
2) "name"
3) "age"判断哈希字段是否存在
hexists key field例如:
127.0.0.1:6379> hexists he name
(integer) 1
127.0.0.1:6379> hexists he sex
(integer) 1将哈希字段的值递增
hincrby key field increment例如:
127.0.0.1:6379> hincrby asd asdf 2
(integer) 3
127.0.0.1:6379> hget asd asdf
"3"
127.0.0.1:6379> hincrby asd asdf 2
(integer) 5
127.0.0.1:6379> hget asd asdf
"5"获取哈希中的所有值
hvals key例如:
127.0.0.1:6379> hvals he
1) "nan"
2) "wanger"
3) "18"内部编码:
-
ziplist(压缩列表):
当哈希类型元素个数小于hash-max-ziplist-entries配置(默认512个)、同时所有值都小于hash-max-ziplist-value配置(默认64字节)时,Redis会使用ziplist作为哈希的内部实现,ziplist使用更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面比hashtable更加优秀。
-
hashtable(哈希表):
当哈希类型无法满足ziplist的条件时,Redis会使用hashtable作为哈希的内部实现,因为此时ziplist的读写效率会下降,而hashtable的读写时间复杂度为O(1)
例如:
127.0.0.1:6379> hset ziplist hash 12335452335235fwgvsfwbhfbwhhfwuesrfhwueywhufgbrewfghusfhwueughsajkifo34ejigji
(integer) 1
127.0.0.1:6379> hmset hash asd fcfg zdf fty
OK集合
唯一且无序的字符串元素的集合。
将一个或多个成员添加到集合中
sadd key member1 member2例如
127.0.0.1:6379> sadd set s1 s2
(integer) 0获取集合所有值
smembers key例如:
127.0.0.1:6379> smembers set
1) "s2"
2) "s1"
3) "s3"删除集合的元素
srem key member1 members2例如:
127.0.0.1:6379> srem set s2
(integer) 1
127.0.0.1:6379> smembers set
1) "s1"
2) "s3"获取元素的长度
scard key例如:
127.0.0.1:6379> scard set
(integer) 2随机获取指定个数的元素
srandmember key [count]例如:
127.0.0.1:6379> srandmember set 1
1) "s1"判断元素是否在集合中
sismember key member例如:
127.0.0.1:6379> sismember set s2
(integer) 0
127.0.0.1:6379> sismember set s3
(integer) 1从集合中弹出指定数量的元素
spop key [count]例如:
127.0.0.1:6379> smembers set
1) "s5"
2) "s4"
3) "s1"
4) "s3"
127.0.0.1:6379> spop set
"s4"
127.0.0.1:6379> spop set 3
1) "s5"
2) "s1"
3) "s3"
127.0.0.1:6379> smembers set
(empty list or set)集合间的并集运算
sunion key1 key2例如:
127.0.0.1:6379> sadd set1 1 2 3
(integer) 3
127.0.0.1:6379> sadd set2 2 3 4 5
(integer) 4
127.0.0.1:6379> sunion set1 set2
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"集合间的交集运算
sinter key1 key2例如:
127.0.0.1:6379> sinter set1 set2
1) "2"
2) "3"集合间的差集运算
sdiff key1 key2例如:
127.0.0.1:6379> sdiff set1 set2
1) "1"
127.0.0.1:6379> sdiff set2 set1
1) "4"
2) "5"内部编码
-
intset(整数集合):
当集合中的元素都是整数且元素个数小于set-max-intset-entries配置(默认512个)时,Redis会选用intset来作为集合的内部实现,从而减少内存的使用。
-
hashtable(哈希表):
当集合类型无法满足intset的条件时,Redis会使用hashtable作为集合的内部实现。
例如:
127.0.0.1:6379> sadd set3 s1 s2 s3
(integer) 3
127.0.0.1:6379> object encoding set3
"hashtable"
127.0.0.1:6379> sadd set4 1 2 3
(integer) 3
127.0.0.1:6379> object encoding set4
"intset"有序集合
每个字符串元素都与一个称为score的浮点值相关联。元素总是按它们的分数排序,因此与Sets不同,可以检索一系列元素
添加元素
zadd key [NX|XX] [CH] [INCR] score1 member1 score2 member2例如:
127.0.0.1:6379> zadd score xx 80 wanger 80 huazai 95 dongdong +inf a
(integer) 0
127.0.0.1:6379> zrange score 0 -1
1) "huazai"
2) "wanger"
3) "dongdong"
4) "a"
+inf和-inf分别表示正无穷和负无穷获取某个成员的分数
zscore key member例如:
127.0.0.1:6379> zscore score dongdong
"95"对成员进行排名,从0开始
zrange key start end [withscores] #升序排列
zrevrange key start end [withscores] #降序排列例如:
127.0.0.1:6379> zadd score 95 huazai 90 wanger 85 dongdong +inf a
(integer) 0
127.0.0.1:6379> zrank score huazai
(integer) 2
127.0.0.1:6379> zrevrank score huazai
(integer) 1
127.0.0.1:6379> zrevrank score a
(integer) 0
127.0.0.1:6379> zrange score 0 -1 WITHSCORES
1) "dongdong"
2) "85"
3) "wanger"
4) "90"
5) "huazai"
6) "95"
7) "a"
8) "inf"获取成员个数
zcard key例如:
127.0.0.1:6379> zcard score
(integer) 4删除成员
zrem key member1 member2例如:
127.0.0.1:6379> zrem score dongdong
(integer) 1
127.0.0.1:6379> zrange score 0 -1
1) "wanger"
2) "huazai"
3) "a"增加成员的分数
zincrby key increment member例如:
127.0.0.1:6379> zincrby score 5 wanger
"95"获取指定分数范围的成员
zrangebyscore key min max [withscores] [limit offset count] #升序
zrevrangebyscore key max min [withscores] [limit offset count] #降序例如:
127.0.0.1:6379> zrangebyscore score 80 90 withscores
1) "dongdong"
2) "85"
3) "wanger"
4) "90"
127.0.0.1:6379> zrevrangebyscore score 95 80 withscores
1) "huazai"
2) "95"
3) "wanger"
4) "90"
5) "dongdong"
6) "85"获取指定分数范围成员个数
zcount key min max例如:
127.0.0.1:6379> zcount score 85 95
(integer) 3删除指定分数范围的成员
zremrangebyscore key min max例如:
127.0.0.1:6379> zremrangebyscore score 85 90
(integer) 2有序集合的交集运算
zinterstore destination numkeys key1 key2 [WEIGHTS weight]-
destination:
交集计算结果保存到这个键。
-
numkeys:
需要做交集计算键的个数。
-
key[key…]:
需要做交集计算的键。
-
weights weight[weight…]:
每个键的权重,在做交集计算时,每个键中
-
的每个member会将自己分数乘以这个权重,每个键的权重默认是1。
-
aggregate sum|min|max:
计算成员交集后,分值可以按照sum(和)、
-
min(最小值)、max(最大值)做汇总,默认值是sum。
最终的结果就是权重乘分数,之后再进行聚合
例如:
127.0.0.1:6379> zadd user 10 wanger 20 huazai 30 dongdong
(integer) 3
127.0.0.1:6379> zadd user1 15 wanger 35 huazai
(integer) 2
127.0.0.1:6379> zinterstore userset 2 user user1
(integer) 2
127.0.0.1:6379> zrange userset 0 -1 withscores
1) "wanger"
2) "25"
3) "huazai"
4) "55"
127.0.0.1:6379> zinterstore user2set 2 user user1 weights 1 0.5 aggregate min
(integer) 2
127.0.0.1:6379> zrange user2set 0 -1 withscores
1) "wanger"
2) "7.5"
3) "huazai"
4) "17.5"有序集合的并集计算
zunionstore destination numkeys key [key ...] [WEIGHTS weight]例如:
127.0.0.1:6379> zadd user 10 wanger 20 huazai 30 dongdong
(integer) 3
127.0.0.1:6379> zadd user1 15 wanger 35 huazai
(integer) 2
127.0.0.1:6379> zunionstore user3set 2 user user1 weights 1 0.5 aggregate max
(integer) 3
127.0.0.1:6379> zrange user3set 0 -1 withscores
1) "wanger"
2) "10"
3) "huazai"
4) "20"
5) "dongdong"
6) "30"内部编码
-
ziplist(压缩列表):
当有序集合的元素小于zset-max-ziplist-entries配置(默认是128个),同时每个元素的值都小于zset-max-ziplist-value(默认是64字节)时,Redis会用ziplist来作为有序集合的内部编码实现,ziplist可以有效的减少内存的使用
-
skiplist(跳跃表):
当ziplist的条件不满足时,有序集合将使用skiplist作为内部编码的实现,来解决此时ziplist造成的读写效率下降的问题.
例如:
127.0.0.1:6379> zadd sortset1 10 a 20 b 30 c
(integer) 3
127.0.0.1:6379> object encoding sortset1
"ziplist"
127.0.0.1:6379> zadd sortset2 10 a 20 b 30 cddddddddddddddddddddddffffffffffffffffffffffffwfwfwggggggggggggggggggwg4yhhhhhhhhhhhhhhhh
(integer) 3
127.0.0.1:6379> object encoding sortset2
"skiplist"Redis持久化
redis提供了两种持久化的方法来将数据以二进制的方式存储到硬盘,一种为在某一时刻生成快照的RDB持久化,另一种为将写入命令追加到aof的持久化文件的持久化
RDB
在 Redis 运行时,RDB 程序将当前内存中的数据库快照保存到磁盘文件中,在 Redis 重启动
时,RDB 程序可以通过载入 RDB 文件来还原数据库的状态。RDB文件非常适合备份以及用于灾难恢复
rdb持久化的过程
-
Redis 会fork 一个子进程。
这样就有了一个子进程和一个父过程。
-
子进程开始将数据集写入临时RDB文件。
-
当子进程完成新的RDB文件的写入后,它将替换旧的RDB文件。
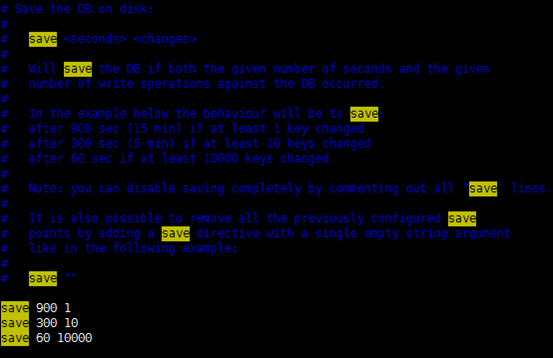
rdb分为手动触发和自动触发,自动触发需要在配置文件中定义
自动触发
rdb持久化默认在配置文件中开启的
vim /etc/redis/6379.conf此配置表示在15分钟内至少修改一次,或者在5分钟内至少修改十次,或者在1分钟内修改10000次会触发rdb操作
是否对快照数据进行压缩存储
rdbcompression yes是否使用CRC64算法进行数据校验,如果开启那么将增加10的性能消耗
rdbchecksum yes指定生成的文件名
dbfilename dump.rdb指定文件存放的目录
dir /var/lib/redis/6379手动触发
rdb的手动触发需要手动调用SAVE或BGSAVE命令
-
SAVE命令:
在当前进程执行,阻塞当前Redis服务器,直到RDB过程完成为止,在主进程阻塞期间,服务器不能处理客户端的任何请求。
-
BGSAVE命令:
当前进程会 fork 出一个子进程,父进程继续处理请求,子进程开始将数据写入临时RDB文件 ,并在保存完成之后向主进程发送信号,通知保存已完成。
因为在子进程被调用,所以 Redis 服务器在BGSAVE 执行期间仍然可以继续处理客户端的请求
AOF
AOF持久性会记录服务器接收的每个写入操作,这些操作将在服务器启动时再次运行,以重建原始数据集。使用与Redis协议本身相同的格式记录命令,并且采用仅追加方式。当日志太大时,Redis可以在后台重写日志。AOF的主要作用是解决了数据持久化的实时性
AOF持久化流程
-
所有的写入命令会追加到aof_buf(缓冲区)中。
-
AOF缓冲区根据对应的策略向硬盘做同步操作。
-
随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩的目的。
-
当Redis服务器重启时,可以加载AOF文件进行数据恢复
AOF持久化策略
-
appendfsync always:
每次将新命令附加到AOF时。
虽然很慢,但是数据不会丢失
-
appendfsync everysec:
每秒钟保存一次。
如果发生灾难,可能会丢失1秒的数据。
-
appendfsync no:
不主动进行同步操作,由操作系统来完成。
更快,更不安全的方法。
通常,Linux使用此配置每30秒刷新一次数据,但这取决于内核的精确调整。
默认采用everysec模式
AOF重写
当AOF太大时,Redis会简单地从头开始将其重写到临时文件中。重写不是通过读取旧的文件,而是由Redis fork一个子进程直接访问内存中的数据,将其转换为写命令同步到新的aof文件,因此Redis可以创建更小的AOF文件,并且在写入新的AOF时不需要读取磁盘。
重写终止后,临时文件将被fsync同步在磁盘上,并覆盖旧的AOF文件。
当aof被重写的过程中又有新数据写入怎么办?这可能会导致数据不一致
新写入的数据会放到旧的aof文件里,同时也会追加到aof的重写缓冲区中,最后替换掉旧的aof文件
AOF配置持久化
vim /etc/redis/6379.conf
是否在后台aof文件重写期间调用fsync,默认为no,表示调用
no-appendfsync-on-rewrite no当前aof文件增长量超过上次afo文件大小的100%时,则触发rewrite,如果为0,则禁用自动触发重写
auto-aof-rewrite-percentage 100aof文件重写最小的文件大小,低于这个值将不会触发重写操作
auto-aof-rewrite-min-size 64mb当子进程重写AOF文件时,每生成32 MB的数据,文件就会把数据落盘,防止单次文件数据过大造成阻塞
aof-rewrite-incremental-fsync yes使用rdb和aof混合持久化方式,会将aof重写操作时的数据状态保存为rdb格式,而重写之后的redis命令会继续追加到rdb数据之后
aof-use-rdb-preamble yesrdb与aof同时存在时,优先使用aof进行数据恢复
欢迎各位一起交流