logstash基本操作及常用日志收集插件
运行一个最基本的logstash管道
Logstash管道有两个必需的元素,input和output,以及一个可选的元素filter。输入插件使用来自源的数据,过滤器插件在您指定时修改数据,输出插件将数据写入目标。
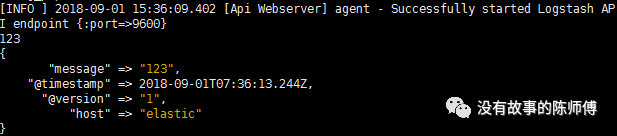
在logstash中使用-e 参数可以在命令行中指定配置
logstash -e 'input {stdin {} } output { stdout { codec => rubydebug } }'
stdin和stdout是logstash内置的插件,他们可以在终端上显示输入输出的结果而方便我们测试
当然也可以将上述配置写在一个配置文件里
vim test.conf
input {
stdin { }
}
output {
stdout {
codec => rubydebug
}
}
然后执行命令logstash -f test.conf,使用-f选项用来指定配置文件,效果是与在命令行中使用-e选项是一样的,当您使用-e或-f时,Logstash会忽略该pipelines.yml文件并记录有关它的警告。如果不加任何参数的话,那么logstash会读取pipelines.yml文件里指定的目录,pipelines.yml默认存在于/etc/logsatsh/pipelines.yml目录
logstash数值类型
-
数组
match =>["datetime", "UNIX", "ISO8601"]
-
布尔
必须是一个true或false
ssl_enable => true
-
字节
一个字段是字节字符串字段表示有效字节的单元。它是一种方便的方式在特定尺寸的插件选项。 支持SI (k M G T P E Z Y)和Binary (TiKimigipiziyiei)单位。二进制单元在基座单元和Si-1024在基底1000。这个字段是大小写敏感的。如果未指定单位,则整数表示的字符串的字节数。
my_bytes => "1113" # 1113 bytes my_bytes => "10MiB" # 10485760 bytes my_bytes => "100kib" # 102400bytes my_bytes => "180 mb"# 180000000 bytes
-
编解码器
codec => "json"
-
哈希
哈希是一个键值对的集合中指定的格式,多个键值对的条目以空格分隔而不是逗号。
match => { "field1" => "value1" "field2" =>"value2" ... }
-
数字
数字必须有效的数字值(浮点或整数)。
port => 33
-
密码
密码是一个字符串的单个值,则不对其进行记录或打印。
my_password => "password"
URI
my_uri =>"http://foo:bar@example.net"
-
路径
一个路径是一个字符串,表示系统运行的有效路径。
my_path =>"/tmp/logstash"
-
转义序列
默认地,转义字符没有被启用。如果你希望使用转义字符串序列,您需要在你的logstash.yml中设置config.support_escapes: true
|
Text |
Result |
|
\r |
carriage return (ASCII 13) |
|
\n |
new line (ASCII 10) |
|
\t |
tab (ASCII 9) |
|
\\ |
backslash (ASCII 92) |
|
\" |
double quote (ASCII 34) |
|
\' |
single quote (ASCII 39) |
条件判断
有时您只想在特定条件下过滤或输出事件。为此,您可以使用条件。
Logstash中的条件查看和行为与编程语言中的条件相同。条件语句支持if,else if以及else报表和可以被嵌套。
条件语法
if EXPRESSION{ ... } else if EXPRESSION { ... } else { ... }
条件表达式支持的比较运算符
比较:==, !=, <, >, <=, >=
正则:=~, !~(是否使用正则匹配)
包含:in,not in (是否包含)
支持的布尔运算符
and,or,nand,xor
支持的一元运算符
!
全局模式支持
只要允许glob模式,Logstash就支持以下模式:
*
匹配任何文件。您还可以使用a *来限制glob中的其他值。例如,*conf匹配所有结尾的文件conf。*apache*匹配apache名称中的任何文件。
**
递归匹配目录。
?
匹配任何一个角色。
[set]
匹配集合中的任何一个字符。例如,[a-z]。还支持排除集合中的任意字符([^a-z])。
{p,q}
匹配文字p或文字q。匹配的文字可以是多个字符,您可以指定两个以上的文字。此模式相当于在正则表达式(foo|bar)中使用垂直条的交替。
\
转义字符。
正则匹配插件grok
描述
grok可以将非结构化日志数据解析为结构化和可查询的内容。此工具非常适用于syslog日志,apache和其他Web服务器日志,mysql日志,以及通常为人类而非计算机使用而编写的任何日志格式。经过grok过滤之后日志会被分成多个字段
Grok的工作原理是将文本模式组合成与日志匹配的内容
grok模式的语法是 %{PATTERN_NAME:capture_name:data_type}
data_type 目前只支持两个值:int 和 float。
PATTERN:NAME为之前定义的文本匹配的模式,而capture_name则是匹配文本的提供的标识符
举个官方文档的例子
如果日志如以下格式,
55.3.244.1 GET/index.html 15824 0.043
那么可以设置grok匹配以下模式 grok { match => { "message" =>"%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes}%{NUMBER:duration}" } }
在grok过滤之后,该事件将添加一些额外的字段:
-
client: 55.3.244.1
-
method: GET
-
request: /index.html
-
bytes: 15824
-
l duration: 0.043
自定义匹配模式
有时logstash没有需要的模式。为此,可以有几个选择。
首先,您可以使用Oniguruma语法进行命名捕获,它可以匹配一段文本并将其保存为字段:
(?<field_name>此处的模式)
例如,后缀日志具有queue id10或11个字符的十六进制值。我可以像这样轻松捕获:
(?<queue_id>[0-9A-F] {10,11})
或者,也可以创建自定义模式文件。
vim patterns
POSTFIX_QUEUEID[0-9A-F] {10,11}
可以设置如下过滤器规则
filter { grok { patterns_dir => ["./patterns"] match => { "message" => %{POSTFIX_QUEUEID:queue_id}" } } }
这样经过过滤之后会多一个标识符为queue_id的字段
-
queue_id: BEF25A72965
一般的正则表达式只能匹配单行文本,如果一个Event的内容为多行,可以在pattern前加“(?m)”
grok过滤器配置选项
|
设置 |
输入类型 |
需要 |
|
break_on_match |
布尔 |
没有 |
|
keep_empty_captures |
布尔 |
没有 |
|
match |
哈希 |
没有 |
|
named_captures_only |
布尔 |
没有 |
|
overwrite |
排列 |
没有 |
|
pattern_definitions |
哈希 |
没有 |
|
patterns_dir |
排列 |
没有 |
|
patterns_files_glob |
串 |
没有 |
|
tag_on_failure |
排列 |
没有 |
|
tag_on_timeout |
串 |
没有 |
|
timeout_millis |
数 |
没有 |
match
match的值类型是哈希,默认值为空
示例
grok { match => {"message" => "Duration: %{NUMBER:duration}" } }
overwrite
overwrite的值类型是阵列,默认值为空
如果你把"message" 里所有的信息通过 grok匹配成不同的字段,数据实质上就相当于是重复存储了两份。所以你可以用 remove_field 参数来删除掉 message 字段,或者用 overwrite 参数来重写默认的 message 字段,只保留最重要的部分。
示例
filter {
grok {
match => {"message"=> "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes}%{NUMBER:duration}"}
overwrite => [ "message"]
}
}
数据修改插件mutate
描述
mutate过滤器允许您对字段执行常规突变。您可以重命名,删除,替换和修改事件中的字段。它提供了丰富的基础类型数据处理能力。包括类型转换,字符串处理和字段处理等。
mutate可用的配置选项
|
设置 |
输入类型 |
需要 |
|
convert |
哈希 |
没有 |
|
copy |
哈希 |
没有 |
|
gsub |
排列 |
没有 |
|
join |
哈希 |
没有 |
|
lowercase |
排列 |
没有 |
|
merge |
哈希 |
没有 |
|
coerce |
哈希 |
没有 |
|
rename |
哈希 |
没有 |
|
replace |
哈希 |
没有 |
|
split |
哈希 |
没有 |
|
strip |
排列 |
没有 |
|
update |
哈希 |
没有 |
|
uppercase |
排列 |
没有 |
|
capitalize |
排列 |
没有 |
convert
convert值的类型是哈希,convert没有默认值
convert可以将字段的值转换为其他类型,例如将字符串转换为整数。如果字段值是数组,则将转换所有成员。可以转换的类型有Boolean,integer,float,string
以下是转换类型的详细解析
-
integer:
字符串被解析; 支持逗号分隔符(例如,字符串"1,000"生成一个值为1000的整数); 当字符串有小数部分时,它们会被截断。
浮点数和小数被截断(例如,3.99变为3,-2.7变为-2)
布尔真和布尔假分别被转换为1和0
-
integer_eu:
相同integer,除了字符串值支持点分隔符和逗号小数(例如,"1.000"生成一个值为1000的整数)
-
float:
整数转换为浮点数
字符串被解析; 支持逗号分隔符和点小数(例如,"1,000.5"生成一个值为一千零一半的整数)
布尔真和布尔假被转换为1.0和0.0分别
-
float_eu:
相同float,除了字符串值支持点分隔符和逗号小数(例如,"1.000,5"生成一个值为一千零一半的整数)
-
string:
所有值都使用UTF-8进行字符串化和编码
-
boolean:
串"true","t","yes","y",和"1"被转换成布尔true
串"false","f","no","n",和"0"被转换成布尔false
空字符串转换为布尔值 false
所有其他值直接通过而不进行转换并记录警告消息
convert可以写成数组格式,数组格式可以将多个字段转成多种类型,并且两个为一组,第一个表示字段,第二个为想转换的数据类型,也可以写成哈希格式,字段与类型一一对应。
示例:
mutate {
convert => ["reqTime","integer","statusCode","integer","bytes","integer"]
convert => {"port"=>"integer"}
}
copy
将现有字段覆盖到另一个字段,并覆盖现有的目标字段,copy的值类型是哈希
示例:
mutate {
copy => {“source_field”=>“dest_field”}
}
gsub
用于字符串的替换,替换的值可以用正则表达式和字符串,gsub配置的值类型为数组,三个为一组,分别表示:字段名称,待匹配的字符串(或正则表达式),待替换的字符串。
在使用正则表达式的时候要注意需要转义的字符用反斜杠转义。
mutate {
gsub => [
#将斜杠替换成_
"fieldname", "/","_",
# 将“\?#-”替换成“-”
"fieldname2","[\\?#-]", "."
]
}
split
将字符串以分隔符分割成数组,只能用于字符串字段,值类型为哈希
示例
mutate {
split =>{"message"=>"," }
}
join
使用分隔符将数组连接成字符串,join的值类型是哈希
示例:
mutate {
join => { "fieldname" => "," }
}
lowercase和uppercase
将字符串转换成小写或大写,值类型默认是数组
mutate {
lowercase => [ "fieldname" ]
uppercase => [ "fieldname" ]
}
merge
合并两个数组或者哈希的字段,若是字符串格式自动转化成数组,值类型是哈希,合并多个字段可以用数组格式
示例
mutate {
merge => {"message"=> "host"}
}
或
mutate {
merge =>["message","host","@version","@timestamp"]
}
rename
重命名某个字段,值类型为哈希
示例
mutate {
rename => {"host" =>"hostname"}
#将host字段重命名为hostname
}
update
更新一个已存在字段的内容,如果字段不存在则不会新建,值类型为哈希
示例
mutate {
update => { "message" =>"asd" }
}
replace
替换一个字段的内容,如果字段不存在会新建一个新的字段,值类型为哈希
示例
mutate {
replace => {"type" =>"mutate"}
#添加一个新的字段type
}
coerce
为一个值为空的字段添加默认值,可以配合add_field,值类型为哈希
示例
mutate {
coerce =>{"field"=>"a123"}
add_field =>{"field"=>"asd"}
}
strip
去掉字段首尾的空格,值类型是数组
示例
mutate {
strip=>["field1","field2"]
}
mutate插件的执行顺序
rename(event) if @rename
update(event) if @update
replace(event) if @replace
convert(event) if @convert
gsub(event) if @gsub
uppercase(event) if @uppercase
lowercase(event) if @lowercase
strip(event) if @strip
remove(event) if @remove
split(event) if @split
join(event) if @join
merge(event) if @merge
时间处理插件date
描述
date插件用于解析字段中的日期,然后使用该日期或时间戳作为事件的logstash时间戳。
日期过滤器对于排序事件和回填旧数据尤其重要,而在实时数据处理的时候同样有效,因为一般情况下数据流程中我们都会有缓冲区,导致最终的实际处理时间跟事件产生时间略有偏差。如果没有此过滤器,logstash将根据第一次看到事件(在输入时),如果事件中尚未设置时间戳,则选择时间戳。例如,对于文件输入,时间戳设置为每次读取的时间。
locale
值类型是字符串
使用IETF-BCP47或POSIX语言标记指定用于日期解析的语言环境。比如设置为en,en-US等.主要用于解析非数字的月,和天,比如Monday,May等.如果是时间日期都是数字的话,不用关心这个值。
match
值类型为数组,默认值为空
用于将指定的字段按照指定的格式解析.比如:
match =>["createtime", "yyyyMMdd","yyyy-MM-dd"]
target
值类型是字符串,默认值为“@timestamp”
将匹配的时间戳存储到给定的目标字段中。如果未提供,则默认更新@timestamp事件的字段。
timezone
值类型是字符串,没有默认值
用于为要被解析的时间指定一个时区,值为时区的canonical ID,一般不用设置,因为会根据当前系统的时区获取这个值.
这里设置的时区并不是logstash最终储存的时间的时区,logstash最终储存的时间为UTC标准时间
时间格式
|
Symbol |
Meaning |
Presentation |
Examples |
|
G |
era |
text |
AD |
|
C |
century of era (>=0) |
number |
20 |
|
Y |
year of era (>=0) |
year |
1996 |
|
x |
weekyear |
year |
1996 |
|
w |
week of weekyear |
number |
27 |
|
e |
day of week |
number |
2 |
|
E |
day of week |
text |
Tuesday; Tue |
|
y |
year |
year |
1996 |
|
D |
day of year |
number |
189 |
|
M |
month of year |
month |
July; Jul; 07 |
|
d |
day of month |
number |
10 |
|
a |
halfday of day |
text |
PM |
|
K |
hour of halfday (0~11) |
number |
0 |
|
h |
clockhour of halfday (1~12) |
number |
12 |
|
H |
hour of day (0~23) |
number |
0 |
|
k |
clockhour of day (1~24) |
number |
24 |
|
m |
minute of hour |
number |
30 |
|
s |
second of minute |
number |
55 |
|
S |
fraction of second |
number |
978 |
|
z |
time zone |
text |
Pacific Standard Time; PST |
|
Z |
time zone offset/id |
zone |
-0800; -08:00; America/Los_Angeles |
|
' |
escape for text |
delimiter |
|
|
'' |
single quote |
literal |
' |
IP分析插件geoip
描述
geoip插件能分析访问的ip分析出访问者的地址信息,GeoLite2数据库是免费的IP地理定位数据库,与MaxMind的GeoIP2数据库相当,但不太准确,geoip 库内只存有公共网络上的 IP 信息,查询不到结果的,会直接返回 null,而 logstash 的geoip 插件对 null 结果的处理是:不生成对应的geoip.字段。
source
这是必须设置的值,值类型是字符串
包含要通过geoip映射的IP地址或主机名的字段。如果此字段是数组,则仅使用第一个值。
database
指定数据库的路径,值类型是路径
Logstash应该使用的Maxmind数据库文件的路径。默认数据库是GeoLite2-City。GeoLite2-City,GeoLite2-Country,GeoLite2-ASN是Maxmind提供的免费数据库,受支持。GeoIP2-City,GeoIP2-ISP,GeoIP2-Country是Maxmind支持的商业数据库。
如果未指定,则默认为Logstash附带的GeoLite2 City数据库。
field
GeoIP 库数据较多,如果你不需要这么多内容,可以通过 fields 选项指定自己所需要的,比如:
fields =>["city_name", "continent_code", "country_code2","country_code3", "country_name", "dma_code","ip", "latitude", "longitude","postal_code", "region_name", "timezone"]
default_database_type
值类型是字符串,默认值为city,可选的值为city和ASN
该插件现在包括GeoLite2-City和GeoLite2-ASN数据库。如果database和default_database_type未设置,将选择GeoLite2-City数据库。要使用包含的GeoLite2-ASN数据库,请设置default_database_type为ASN。
多行编解码插件multiline
描述
此编解码器的最初目标是允许将来自文件的多行消息连接到单个事件中。例如,将Java异常和堆栈跟踪消息加入单个事件中。
negate
值类型是布尔值,默认值为false
否定正则表达式模式。negate是对pattern的结果做判断是否匹配,默认值是false代表匹配,而true代表不匹配,这里并没有反,因为negate本身是否定的意思,双重否定表肯定。
pattern
必须设置的,值类型是字符串
pattern后面加要匹配的正则表达式,可以使用grok正则表达式的模板来配置该选项。
what
这是必须的设置,值可以是任何的:previous,next
如果模式匹配,事件是否属于下一个或上一个事件,previous 值指定行匹配pattern选项的内容是上一行的一部分。 next 指定行匹配pattern选项的内容是下一行的一部分。
pattern_dir
值类型是数组,默认值为[]
Logstash默认带有一堆模式,如果你要添加其他模式,可以将匹配模式写到文件里
例如
NUMBER \d+
示例
codec=>multiline {
pattern =>"^\["
negate => true
what =>"previous"
}
如果没有匹配到以“[”开头的行,那肯定是属于前一行的。
使用logstash收集日志操作
使用logstash收集NGINX日志
vim logstash-nginx.conf
input {
file { #使用file插件收集日志
path =>"/var/log/nginx/*.log" #指定日志路径
start_position =>"beginning" #指定日志读取的位置,默认是end,beginning表示从文件开始的位置读取,而end表示从上次读取结束后的日志文件开始读取,但是如果记录过文件的读取信息,这个配置也就失去作用了。
}
}
filter {
if [path] =~ "access" { #判断是否是access日志
mutate { replace => { type =>"nginx_access" } } #如果是access日志则添加一个type字段
grok {
match => { "message"=> "%{COMBINEDAPACHELOG}" } #使用grok插件过滤access日志,将其转化成多个字段,%{COMBINEDAPACHELOG}是grok定义好的表达式
}
date {
match => [ "timestamp", "dd/MMM/yyyy:HH:mm:ss Z" ] #将收集到的日志日期作为时间戳
}
}
else if [path] =~ "error"{ #判断是否是错误日志
mutate { replace => { type =>"nginx_error" } } #如果是错误日志,则添加一个type字段
grok {
match => { "message"=> "(?<datetime>\d{4}/\d{2}/\d{2} \d{2}:\d{2}:\d{2})\[(?<errtype>\w+)\] \S+: \*\d+ (?<errmsg>[^,]+),(?<errinfo>.*$)" } #使用grok插件过滤error日志,将其转化成多个字段,这里的表达式是自己定义的
}
date {
match => [ "timestamp", "dd/MMM/yyyy:HH:mm:ss Z" ] #将收集到的日志作为时间戳
}
}
}
output {
if [type] =~ "access" { #如果收集到的日志为access类型,那么就将日志输出到access的索引
elasticsearch {
hosts =>["192.168.179.134:9200"]
index =>"nginx_access-%{+YYYY.MM.dd}"
}
}
else if [type] =~ "error"{ #如果收集到的日志为error类型,那么就将日志输出到error的索引
elasticsearch {
hosts =>["192.168.179.134:9200"]
index =>"nginx_error-%{+YYYY.MM.dd}"
}
}
}
使用logstash结合rsyslog收集系统日志
rsyslog是日志收集工具,现在很多Linux都自带rsyslog,用其替换掉syslog。
rsyslog本身有一个配置文件/etc/rsyslog.conf,里面定义了日志文件,以及相应保存的地址。
一般通过rsyslog来收集日志信息,并发送到logstash。
配置rsyslog
vim /etc/rsrslog.conf
*.* @@192.168.179.134:5514
配置logstash
vim rsyslog.conf
input {
syslog {
host =>"192.168.179.134"
port => 5514
}
}
output {
stdout {
codec => rubydebug
}
}
在命令行输入logger "helo world"可以查看logstash的输出
logger是一个shell命令接口,可以通过该接口使用Syslog的系统日志模块,还可以从命令行直接向系统日志文件写入一行信息。
使用Redis作为消息队列来收集日志
redis服务器是logstash官方推荐的broker(代理人)选择,broker角色也就意味着会同时存在输入和输出两个插件,发送消息的也就是输出插件被称作生产者,而接收消息的也就是输入插件被称作消费者。
redis消息队列作用说明:
-
防止Logstash和ES无法正常通信,从而丢失日志。
-
防止日志量过大导致ES无法承受大量写操作从而丢失日志。
-
应用程序(php,java)在输出日志时,可以直接输出到消息队列,从而 完成日志收集。
补充:如果redis使用的消息队列出现扩展瓶颈,可以使用更加强大的kafka,flume来代替。
安装Redis
wget http://download.redis.io/releases/redis-4.0.11.tar.gz #下载Redis源码
tar -zxfredis-4.0.11.tar.gz #解压Redis源码
cp -r redis-4.0.11 /usr/local/
mv redis-4.0.11/ redis
cd /usr/local/redis/
cp redis.conf bin/
make PREFIX=/usr/local/redis install #编译安装Redis
echo "export PATH=$PATH:/usr/local/redis/bin" >> /etc/profile 将Redis加入环境变量
启动Redis
1.前端模式启动
直接运行bin/redis-server将以前端模式启动,前端模式启动的缺点是ssh命令窗口关闭则redis-server程序结束,不推荐使用此方法
redis-server
2.后端模式启动
修改redis.conf配置文件, daemonize yes 以后端模式启动
vim /usr/local/redis/bin/redis.conf
daemonize yes
执行如下命令启动redis:
redis-serverredis.conf
连接redis
redis-cli
关闭Redis
强行终止redis进程可能会导致redis持久化数据丢失。正确停止Redis的方式应该是向Redis发送SHUTDOWN命令,命令为:
redis-cli shutdown
写redis生产者和消费者配置文件
vim redis-consumer.conf
input {
redis { #定义redis消费者的配置
data_type => "list" #定义redis数据类型,redis支持三种数据类型,list,channel,pattern_channel,同的数据类型会导致实际采用不同的 Redis 命令操作,其中list,相当于队列;channel相当于发布订阅的某个特定的频道;pattern_channel相当于发布订阅某组频道。
key =>"redis_logstash" #定义redis列表或者频道的名称
host =>"192.168.179.134" #定义redis服务器的主机名
port => 6379 #定义redis服务器的端口
db => 1 #定义redis数据库编号
}
}
output {
elasticsearch { #输出到elastic上
hosts =>"192.168.179.134" #定义elasticsearch的地址
index => "logstash_redis-%{+YYYY.MM.dd}" #添加一个elasticsearch索引
}
stdout { codec => rubydebug }
}
vim redis-producer.conf
input { stdin { } }
output{ #定义redis生产者的配置
redis {
host =>"192.168.179.134" #同redis消费者的配置
data_type => "list"
db => 1
port => 6379
key => "logstash_redis"
}
}
启动redis和elasticsearch,logstash
redis-server/usr/local/redis/bin/redis.conf #后台运行redis
redis-climonitor #开启redis监控
$ /elasticsearch/elasticsearch-6.4.0/bin/elasticsearch #开启elasticsearch
[root@elasticelasticsearch-head]# grunt server #开启elastic-head插件
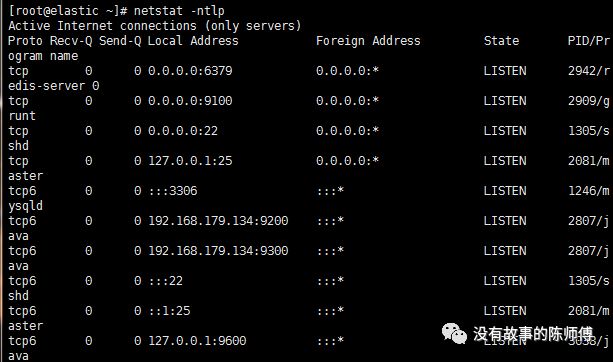
logstash -f/etc/logstash/conf.d/ #启动logstash
netstat-ntlp #查看端口是否监听
在head插件上查看索引是否创建成功
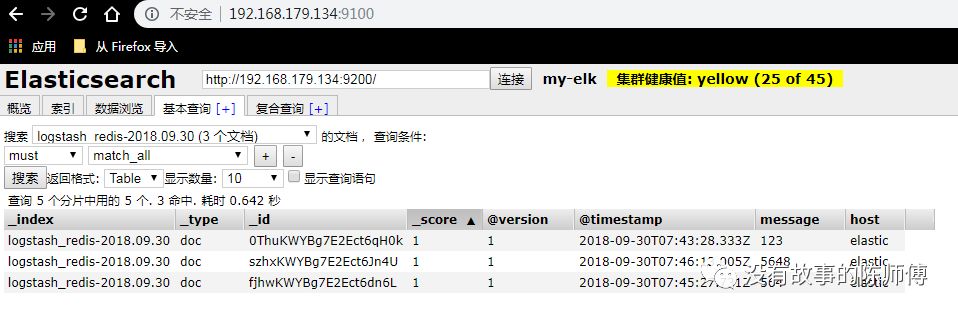
使用logspout结合elk收集docker日志
随着容器的大量使用,现在docker已经在很多生产环境得到实践,不过,容器的日志,状态,确是一个大问题,我们知道,一般可以使用命令docker logs 来查看一个特定的容器,那如果想要收集当前机器所有容器的日志呢?或许我们可以将日志的输出记录到主机磁盘中,然后使用logstash 去收集,在你不考虑服务器性能的情况下,这当然也是一种方法,在这里我要介绍的使用logspout去进行docker日志的收集,这需要在你的主机上运行一个logspout的容器,负责将同一个主机上其他容器的日志,根据route设定,转发给不同的接收端,它是一个无状态的容器化程序,并不是用来管理日志文件或查看日志的,它主要是用于将主机上容器的日志发送到其它地方。目前它只捕获其它容器中的程序发送到stdout和stderr的日志。
Logspout 是 Docker 流行和轻量级的基于Alpine Linux构建的日志路由器,它将附加到主机中的所有容器,并将 Docker 日志流输出到 syslog 服务器
安装docker
1、安装依赖包
yum install-y yum-utils device-mapper-persistent-data lvm2
2、添加国内yum源
yum-config-manager--add-repo https://mirrors.ustc.edu.cn/docker-ce/linux/centos/docker-ce.repo
3、更新yum软件源缓存,并安装docker-ce
yummakecache fast && yum install docker-ce
4.设置镜像加速器,在/etc/docker/daemon.json中写入如下内容
{
"registry-mirrors": [
"https://registry.docker-cn.com"
]
}
阿里云镜像加速器地址 https://cr.console.aliyun.com/cn-hangzhou/mirrors
5.启动docker服务
systemctlstart docker
安装docker-comose (不是必须的)
curl -L "https://github.com/docker/compose/releases/download/1.22.0/docker-compose-$(uname-s)-$(uname -m)" -o /usr/local/bin/docker-compose
pull一个logspout的镜像
docker pull gliderlabs/logspout
写logstash配置文件并启动
vimlogspout.conf
input {
tcp {
port => 5140
}
udp {
port => 5140
}
}
output {
stdout {
codec => rubydebug
}
elasticsearch {
hosts =>"192.168.179.134"
index => "logspout"
}
}
logstash -f logspout.conf
启动logspout的容器
docker run --name="logspout" --volume=/var/run/docker.sock:/var/run/docker.sock --publish=192.168.179.134:8000:80
gliderlabs/logspout syslog+tcp:192.168.179.134:5140 #将收集到的日志转发至192.168.179.134:5140,默认采用udp协议,我修改成了tcp协议
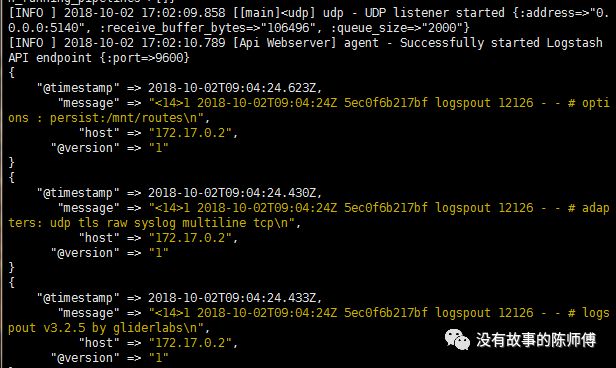
logspout容器一启动就开始进行容器日志的转发,并打印到终端和elastic上
logspout将从没有-t选项启动的其他容器中收集日志,并且这些容器的日志驱动配置为系统默认的兼容journald和json-file的日志类型(即这些容器的日志可以通过docker logs命令查看)。
关于logspout的详细用法可以查看logspout的docker仓库 https://hub.docker.com/r/gliderlabs/logspout/
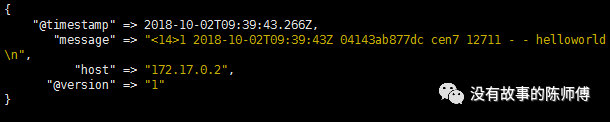
我再启动一个新的centos容器,并输出一些信息
docker run -d --name=cen7 centos echo "helloworld" >>/var/log/lastlog
使用curl检查日志流
通过使用logspout的httpstream模块,可以通过curl时时查看logspout路由的日志,甚至可以不提供日志路由的URI:
curl 192.168.179.134:8000/logs

忽略指定的容器
可以通过在启动容器时设置环境变量来告诉logspout忽略特定容器,如下所示:
docker run-d -e 'LOGSPOUT=ignore' image
或者,通过在运行logspout时通过设置环境变量来添加您定义的标签:
docker run --name="logspout" \
-e EXCLUDE_LABEL=logspout.exclude \
--volume=/var/run/docker.sock:/var/run/docker.sock\
gliderlabs/logspout
docker run -d --label logspout.exclude=trueimage
指定特定的容器
可以通过在URI上设置过滤器参数来告诉logspout仅包含某些容器:
指定容器名包含db的容器
docker run \
--volume=/var/run/docker.sock:/var/run/docker.sock\
gliderlabs/logspout\
raw://192.168.10.10:5000?filter.name=*_db
或者指定容器id:
docker run \
--volume=/var/run/docker.sock:/var/run/docker.sock\
gliderlabs/logspout\
raw://192.168.10.10:5000?filter.id=3b6ba57db54a
将容器日志直接路由至logstash
这样需要修改模块配置文件modules.go
添加logspout-logstash模块
_ "github.com/gliderlabs/logspout/transports/udp"
_"github.com/looplab/logspout-logstash"
重新编写dockerfile并构建镜像
FROM gliderlabs/logspout:latest
COPY./modules.go /src/modules.go
重新构建logspout后,可以通过指定环境变量ROUTE_URIS=logstash://host:port来给定logstash服务器的URI,当然也可以直接在dockerfile中指定logstash URI的环境变量
ENVROUTE_URIS=logstash://host:port。
docker run --name="logspout" --volume=/var/run/docker.sock:/var/run/docker.sock -e ROUTE_URIS=logstash://192.168.179.134:5140 registry.cn-beijing.aliyuncs.com/andyyoung01/logspout-logstash
在https://github.com/andyyoung01/logspout-logstash/tree/test_branch/custom上已经配置好了,可以直接clone重新构建
由于笔记尚未写完,先将部分笔记发公众号,等全部写完再丢github
参考链接:https://www.elastic.co/guide/en/logstash/current/index.html
如果有想一起交流的朋友可以扫描下方二维码进入群聊