大家好,我是乔克。
今天给大家分享的主题是《闲聊Docker》,大家的工作都比较忙,但是也要劳逸结合,所以“闲”是忙里偷闲,而“聊”是只动嘴不动手,整个分享过程中不会去动手实践,也不会去教大家如何build镜像,如何run容器,而只做纯粹的闲聊,我是一个“纯粹”的人。
整个PPT比较简洁,基本都是一些图片或者流程图,我也是跟着这些图片来进行分享,想到哪里就说到哪里,有时候会啰里吧嗦,有时候可能会牛头不对马嘴,在分享的过程中,如果有纰漏的地方,大家可以记下来,分享完后咱再来讨论。
现在进入正题,整个分享主要分为以下5个部分。第一部分是让大家感受一下Docker的魅力。第二部分是为大家分享一下Docker为什么这么火,为什么大家喜欢它,它背后的推手是什么。第三部分来分享一点历史,简单看看Docker背后的那些故事。第四部分主要带大家了解一下Docker背后的技术,它的技术底座是什么,怎么实现的。第五部分简单介绍一下Docker的常用操作。但是整个分享过程我会紧扣原则:只动嘴不动手。

现在,我们看看第一部分:感受Docker的魅力。不知道大家有没有在自己电脑上安装过虚拟机,然后创建虚拟机安装操作系统,再部署需要的应用。其实从我的描述中,大概可以感知到过程是复杂的,我们需要先安装虚拟机软件,进行整体的虚拟化操作,然后再创建虚拟机,安装操作系统,最后还要优化操作系统,安装需要的软件。整个过程就算是”熟手“至少也需要10分钟以上,如果是新手,就需要慢慢”百度“了。
我们平时在做企业级虚拟化的时候,也大致是这种流程,可以想象一下:如果同时要创建的虚拟机非常多,要新建的服务非常多,是不是非常的头疼?我曾经一天创建500台虚拟机,然后要安装不同的软件,我只能说脑瓜嗡嗡的。
但是,如果使用Docker容器呢?
我们只需要在服务器上安装Docker守护进程,然后使用一条简短的命令就可以起一个应用。
如果要起500个应用,大不了执行500次命令。因为人都是感性的动物,擅长快思考,所以会觉得500这个数字比较庞大,但是起一个容器的时间一般秒数级别,和创建虚拟机的10分钟以上相比,可就太优秀了。
从这里大家有没有意会到Docker的魅力?简单、快速,对工作强度大的开发来说,简直就是福音:不用等创建虚拟机、初始化应用的时间就可以把服务部署起来进行调试,提升了不少的工作效率。
这就是Docker的魅力之一,具体的感受大家可以空闲的时候自己试试,如果感受不强烈,可以和创建虚拟机对比着来。
OK,带大家简单感受了一下Docker的魅力(不知道大家有没有感受到),但是仅仅这样就会让Docker火吗?
在进入第二阶段之前,我先来介绍一下容器技术。容器技术的本质是想实现隔离,那只有Docker实现了么?其实早在1979年的时候,就有了容器技术的概念,其中的chroot(Change Root)就是容器技术的实现,只是比较简单粗暴,后来谷歌内部大量使用的CGroups也是容器技术,后来捐给了Linux,融入内核中,再后来Linux自己也推出了LXC(Linux Container)容器,再到后面的Docker。可以看出先辈们在容器技术领域的探索很早就有了,那为什么偏偏Docker火了?
现在我们来看看Docker的背后推手到底是什么。
我们先看下面左边这幅图,这其实是单机时代的逻辑图,我们会在一台物理机上部署很多应用,比如Mysql,Kafka,Redis等,非常多的应用在一台机器上,这就带来了以下的问题:1、相互影响,假如有一个IO密集型应用,频繁的读写磁盘会导致磁盘性能降低,从而影响其他应用。2、由相互影响其实就可以想到隔离性差,这个就不赘述了。3、维护难度大,如果某个应用引发BUG,但是这个BUG必须要重启服务器才能解决,那么多应用,影不影响业务先不说,它本身的重启就非常困难。
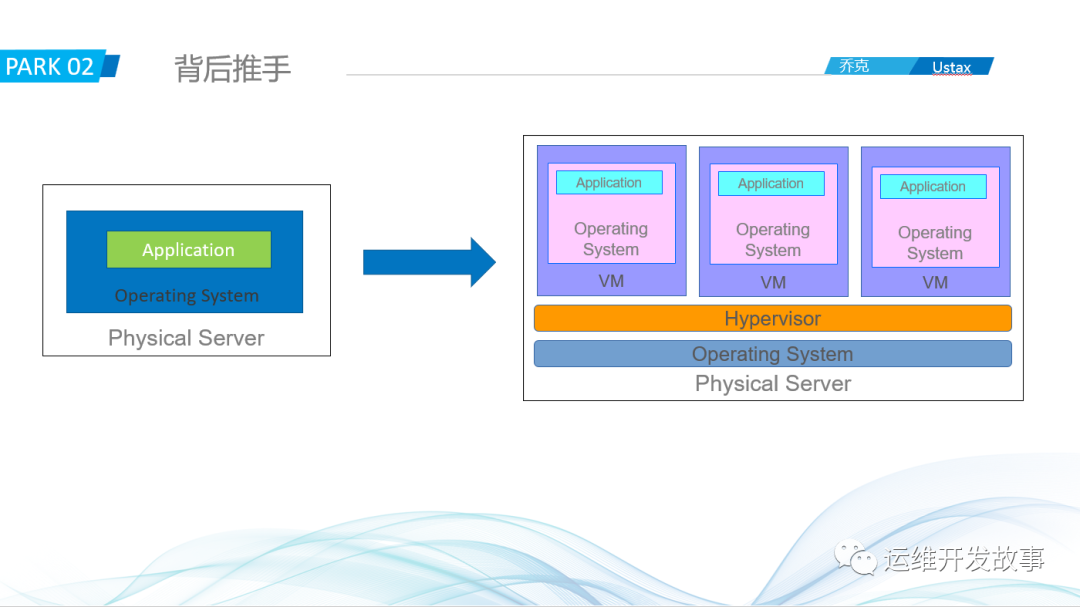
为了解决这些问题,先辈们就探索了右边这幅图:使用虚拟化技术。通过在一台主机上创建不同的虚拟机,每个虚拟机跑不同的应用来实现隔离,这样应用之间不会相互影响,如果某个虚拟机出现BUG,只需要重启相应的虚拟机即可,不会影响其他应用。咋一看,这确实是完美的解决方案,但是其又引入了新的问题:1、资源浪费严重。从图中就可以看出,每台虚拟机都要部署一个操作系统,如果一个操作系统占用资源是2G,那100台就是200G,大家可以想想这种浪费程度。2、维护性难度依然大。虚拟机数量多本身就会带来很大的维护成本,还引入了新的技术,学习成本也不低,而且虚拟机的迁移等成本比较高。
除了这些,这两种都有一个共同的问题,那就是打包部署比较繁琐,而且相同的应用在不同的环境可能会因为不一致的环境问题引发莫名的BUG,可能你的应用在开发环境是OK的,但是到测试环境死活起不来或者测不过,我想大家都遇到过这个问题。
那Docker容器是怎么解决的呢?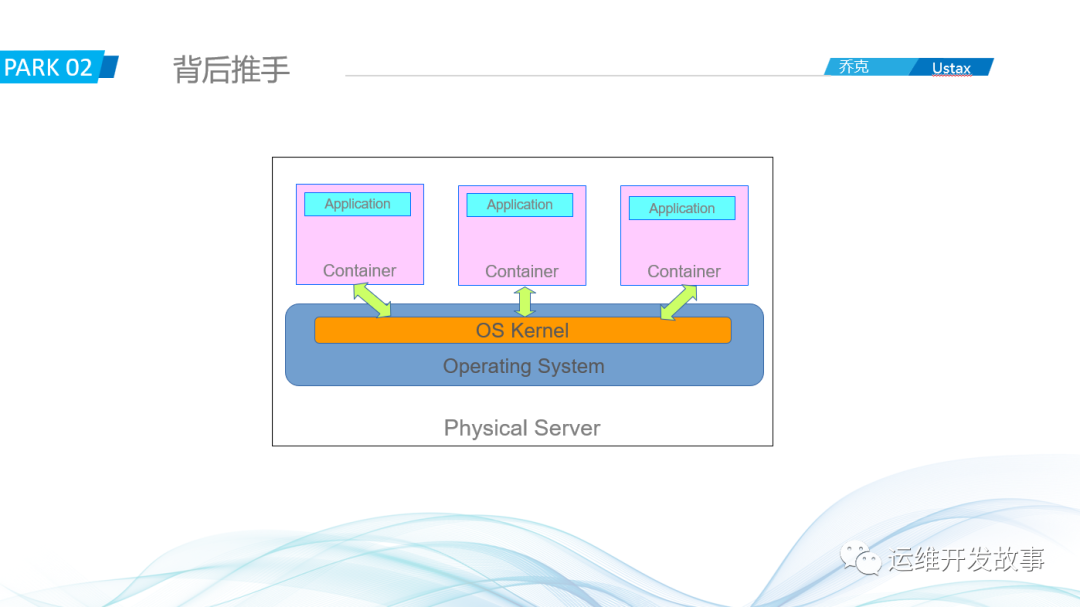
咋一看,是不是像是把单机和虚拟机进行了有机结合:直接在单机上部署应用,节约了资源,使用容器技术实现了隔离,一切都那么的完美。但这并不是让它大火的原因,因为我们上面说过:容器并不是新鲜玩意。
Docker真正火的是在应用打包部署上的革新:它通过Docker镜像技术,把应用连同它的运行环境一起打包,不论在什么地方,什么环境,运行这个镜像,都能得到一致性的环境,真正的解决了环境一致性的问题,深受开发人员的喜爱。
从这,我们就可以总结一下Docker火起来的原因:1、更高效地利用系统资源,避免资源浪费
2、更快的启动时间,比虚拟机快数倍
3、一致的运行环境,避免环境问题导致其他异常
4、更轻松的迁移、扩展和维护,都是通过镜像来操作,所以一切变得很简单了。

Docker这么好,在社区也这么火,它是容器领域的霸主吗?并不是,现在给大家介绍一下Docker背后的那些故事。

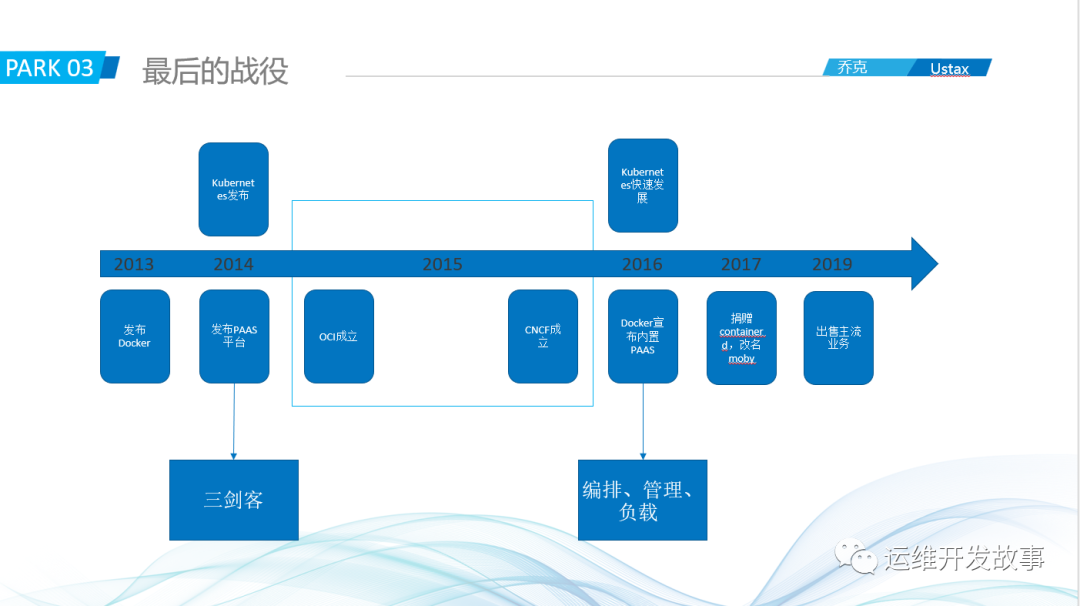
可以看到整体的时间线,在2013年的时候dotCloud公司开源了Docker,刚开始,大厂的技术大佬们觉得Docker就是新瓶装旧酒,没啥新奇玩意,但是随着人们的尝试,发现Docker的简单、易用以及它的镜像技术非常的不错,社区开始追捧。大厂的大佬们也是眼疾手快,马上加入进来。到2014年,大部分大厂都多多少少和Docker有合作,微软甚至想花40亿收购Docker公司,但是被拒绝了。
Docker只是一个启停应用的小工具,Docker公司也注意到了这点,所以在2014年的时候Docker公司发布了三剑客(docker swarm、docker compose、docker machine),宣布正式进入PAAS,这时候有些大厂就不开心了,比如红帽、coreos等这些本身就是做PAAS生意的,这些公司就宣布退出和Docker的合作。在这期间,不得不说一下谷歌这个公司,其实在Docker刚开始火的时候,谷歌就与Docker公司沟通,能不能把容器运行时从Docker弄出来一起维护,共同制定标准,但是被Docker拒绝了,再后来谷歌发布Kubernetes,也曾想把它捐给Docker,由Docker来维护,但是也被Docker拒绝了,因为Docker公司觉得Kubernetes和他们自己的三剑客是直接竞争关系。
这样来回拉扯,时间来到2015年,随着很多大厂的退出合作,Docker公司也不想和大家闹的太僵,就牵头要和大家一起成立一个基金会(OCI),共同制定容器和镜像的标准。这些大佬当然愿意,因为这样Docker就不会一家独大,其他公司也可以根据这些标准来玩自己的容器了。
但是,Docker是出人不出力,其他公司也发现了这点,所以谷歌等其他公司就搞了一个CNCF的基金会,打算以Kubernetes为中心构建云原生技术。在2016年的时候Kubernetes快速发展,给Docker的三剑客来了一个降维打击,根本没法玩,以至于Docker想把那些功能全放Docker,当然结果是失败的,再后来到2017年,Docker公司发现在开源领域根本玩不过那些大厂,就把container捐给了CNCF,专注企业服务。随着收益不好,在2019年Docker公司就把主流业务都出售了,也宣布由Docker引发的战争真正的结束了。
docker公司的故事结束了,但是docker容器并没有结束,它现在依然活跃在人们的视野中。下面我们来看看Docker的背后技术。

首先来看看整体的运行逻辑,从图可知,主要分为三部分:客户端、服务端和镜像仓库。
客户端发起操作,服务端接收到命令会进行解析,如果涉及到镜像操作,比如拉取,就会从镜像仓库把镜像拉取到本地,然后会在本地进行启动操作,整个运行逻辑是非常简单的。
我们再来看看它的系统架构。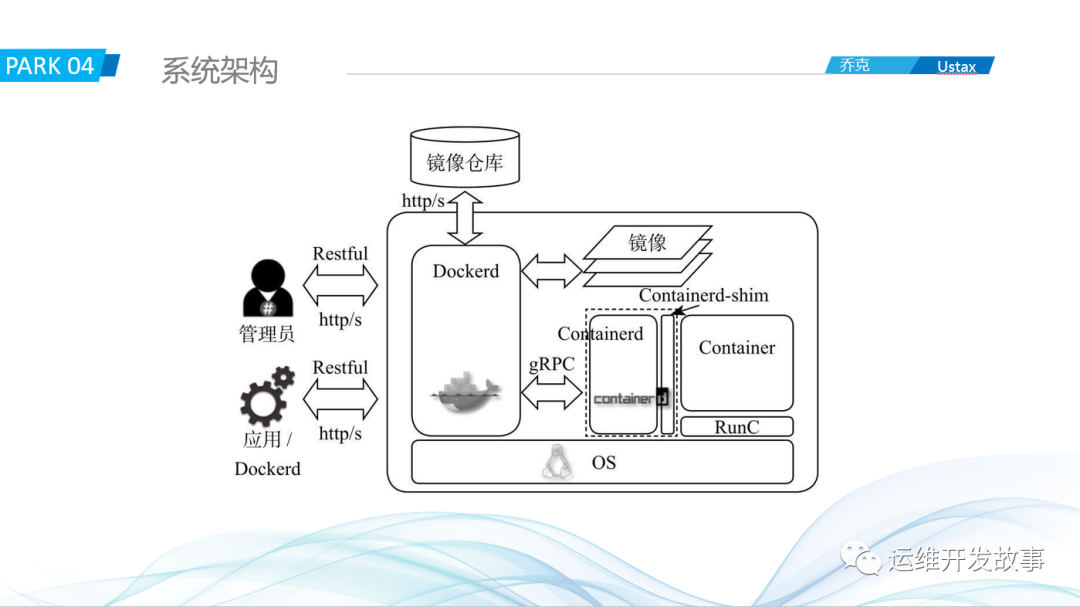
整个系统主要涉及dockerd,containerd,runc和container-shim。在docker1.11版本之前,所有的事情都是由dockerd来完成,在1.11之后,就拆分成上面这个样子。dockerd是面向用户的,是底层API的封装,不进行真正的业务逻辑处理,containerd是处理业务逻辑的,runc负责实际的操作,比如启动容器,而docker-shim则负责处理信号,比如Kill信号等。从整体来看,Docker现在的核心其实是在containerd,runc和containerd-shim,所以在kubernetes1.20.X版本中,建议直接使用containerd而不是docker。
介绍完系统架构,我们再看来来Docker的技术底座。
Docker的技术底座主要是namespace,cgroup以及unionfs。这些其实都是Linux内核的东西,所以说Docker是强依赖Linux内核的。
namespace主要实现资源的隔离,为用户提供干净的运行环境。在实际中,主要用到下面的这几种隔离技术:
-
pid namespace:隔离进程 -
mnt namespace:隔离文件系统 -
net namespace:隔离网络 -
ipc namespace:隔离信号量 -
uts namespace:隔离主机名等 -
user namespace:隔离用户、用户组等
cgroup主要是用来实现资源限制的。容器不像虚拟机,虚拟机在创建的时候制定多少资源就用多少,容器如果没有制定就会使用主机的整体资源,为了限制容器对资源的使用,就用cgroups技术来实现,主要限制比如内存、cpu。比如主机有8核32G的配置,可以给某个容器限制只使用2C4G。
unionfs叫做联合文件系统,就是把不同位置的目录挂载到同一文件中,最终形成一个虚拟的文件系统。在早期,docker主要是使用device mapper,但是配置比较麻烦,现在基本都是overlayfs,比如redhat,centos默认就是overlayfs。
我们可以看看联合文件系统OverlayFS的视图。
从图中可以看到,OverlayFS只有上层目录和下层目录,如果上层和下层目录里的文件有冲突,会选择使用上层的文件,合并层其实是一个视图层。我们的容器镜像就是通过这一层一层的挂上去的。
下面我们再看看Docker的网络部分。容器只是一个单一的实体,我们最终的目的是要提供服务,要服务就离不开网络。
Docker主要实现了上面四种网络:
-
bridge:桥接,就是通过网桥把所有的容器链接起来 -
host:直接使用主机的网络 -
null:不配置任何网络,让人们自定义。 -
container:使用容器网络,Kubernetes的Pod中的所有容器就是通过这种方式进行连接的
在实际中,bridge和container用的比较多。
下面我会介绍一下在同一主机和不同主机之间,容器是怎么进行访问的。
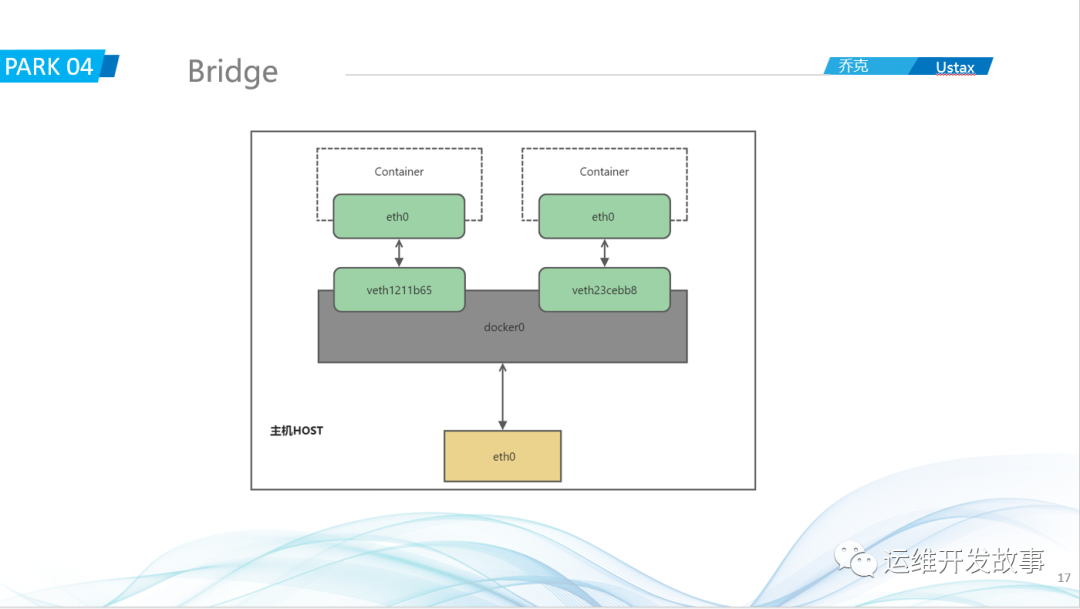
同一主机上的容器进行交互比较简单,当我们安装好Docker之后,会在服务器上起一个docker0的网桥,之后起的所有容器都会桥接在docker0网桥上,这里就可以把docker0看成是一个交换机,不同的容器相当于不同的电脑,这些电脑都通过一根网线和交换机进行连接,网关是docker0的地址。如果容器A要访问容器B,请求会直接到达网关docker0,docker0里面会有地址表,然后根据地址表把请求转发容器B。
如果是跨节点呢?
跨节点通信,目前常用的技术主要有:1、基于二层的vxlan隧道技术
2、基于三层的SDN网络技术
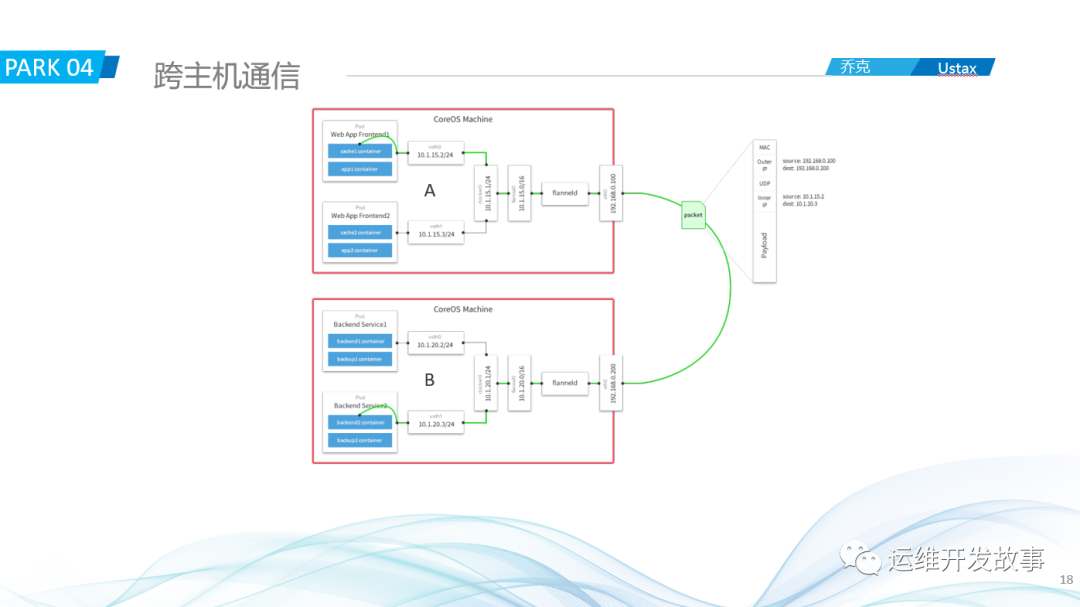 如上图,这里介绍基于vxlan实现的flannel的工作模式。
如上图,这里介绍基于vxlan实现的flannel的工作模式。
首先会在两台主机上部署flannel,其flanneld进程会维护各个主机的信息,包括主机的IP以及容器的网段等。主机A上的容器a(10.1.15.2)要访问主机B上的容器b(10.1.20.3),请求会先到docker0网桥,网桥判断目的地址不是同一个网络,就会把请求通过默认路由的形式转发到主机的flannel0网卡,然后把信息给到flanneld,flanneld会根据目标地址查询所在的主机以及MAC地址,然后把这些信息封装到请求头里,通过eth0发出去,主机B收到请求会判断是不是本机的,如果是就丢给flanneld进行解包,然后再一次进行下一步直到达到容器b。这就是跨主机通信的大概流程。
好了,到现在基本要容器涉及到的主要技术进行了介绍,最后我们还是来看看Docker的常用操作。
首先来看看docker主要涉及的命令。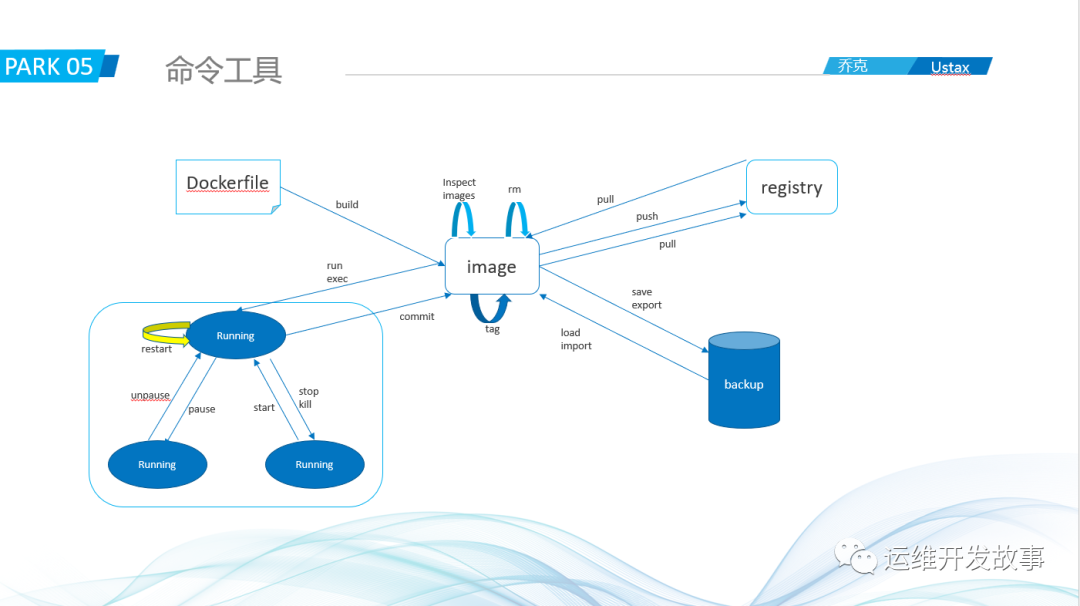
从上面可以知道,这些主要的docker命令都是围绕docker镜像的,比如通过Dockerfile build一个镜像,然后把镜像push到镜像仓库。这个图中基本可以知道它们之间的关系。
最后,再来看看Dockerfile是什么样子。
如图就是一个简单的Dockerfile,它通过不同的命令把我们的需求叠加起来,最后成为我们想要的镜像。其中FROM是Dockerfile的开头,表示基础镜像,LABEL就是打标签,ENV是设置一些环境变量,RUN用来执行命令,ADD用来把本地文件添加到镜像,COPY表示把本地文件拷贝到镜像,WORKDIR表示设置工作目录,EXPOSE表示声明要暴露的端口,CMD用来执行容器运行时的命令。除此之外还有ENTRYPOINT等命令。
好了,今天的分享就到这里,谢谢大家。
如果我的文章对你有所帮助,还请帮忙点赞、在看、转发一下,你的支持会激励我输出更高质量的文章,非常感谢!
你还可以把我的公众号设为「星标」,这样当公众号文章更新时,你会在第一时间收到推送消息,避免错过我的文章更新。
我是 乔克,《运维开发故事》公众号团队中的一员,一线运维农民工,云原生实践者,这里不仅有硬核的技术干货,还有我们对技术的思考和感悟,欢迎关注我们的公众号,期待和你一起成长!